
페이징 최적화를 진행해 보았다.
페이징 최적화에는 크게 두 가지 방법이 있다.
NoOffset과 커버링 인덱스를 사용하는 방법이 존재한다.
이번에 프로젝트에서 게시글과 댓글의 페이징 최적화를 진행하였는데, 이 글은 게시글에 관해서만 작성할 예정이다.
일반적인 페이징 쿼리
기존의 코드는 아래와 같았다.
public interface BoardRepository extends JpaRepository<Board, Long> {
Page<Board> findAll(final Pageable pageable);
}
@Transactional(readOnly = true)
public BoardAllResponse findAllBoards(final Pageable pageable) {
Page<Board> sortedBoards = boardRepository.findAll(sortByIdWithDesc(pageable));
BoardPageInfo boardPageInfo = BoardPageInfo.from(sortedBoards);
List<BoardResponse> boards = sortedBoards.stream()
.map(BoardResponse::from)
.collect(collectingAndThen(toList(), Collections::unmodifiableList));
return BoardAllResponse.of(boards, boardPageInfo);
}
private PageRequest sortByIdWithDesc(final Pageable pageable) {
return PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(), Sort.by(BOARD_ID).descending());
}
위의 쿼리는 다음과 같았다.
SELECT *
FROM BOARD
ORDER BY id DESC
OFFSET 페이지 번호
LIMIT 페이지 사이즈위 쿼리의 문제점은 OFFSET 번호가 뒤로 갈수록 느려진다는 점이다.
이유는 뒤페이지를 읽어야 한다면, 앞에 읽었던 행을 다시 읽어야 한다는 것 때문이다.
정작 앞의 부분은 필요로 하지 않기에 버리게 된다.
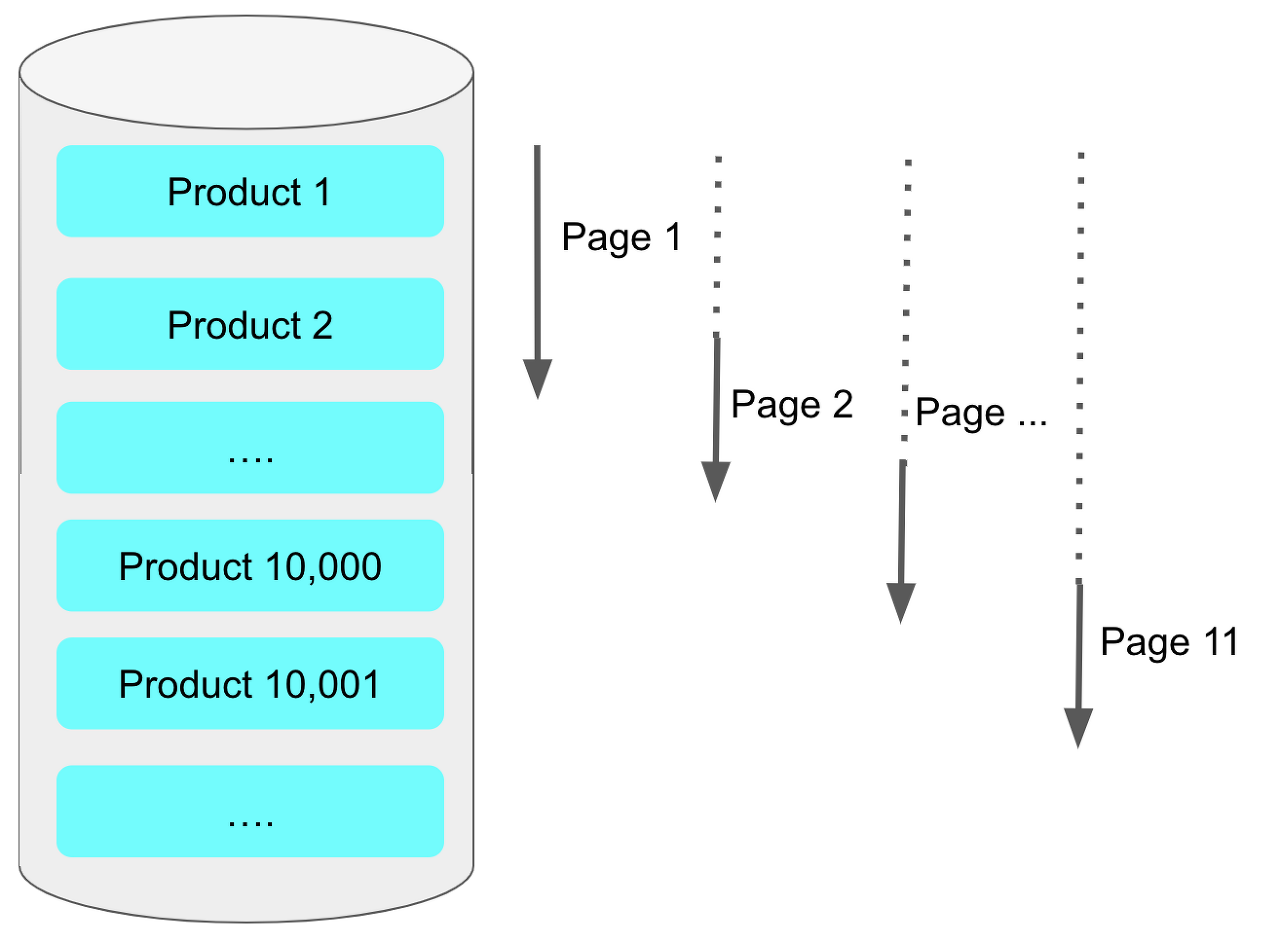
위를 해결하기 위해 선택한 방법은 NoOffset방식이다.
NoOffset
우선 NoOffset이란 페이지 번호가 없는 더 보기 방식이다.

그렇다면 왜 NoOffset을 사용할까?
NoOffset은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만을 읽도록 하는 방식이다.
이를 적용한 코드를 통해 알아보자.
public class BoardRepositoryCustomImpl implements BoardRepositoryCustom {
private final JPAQueryFactory jpaQueryFactory;
public BoardRepositoryCustomImpl(final JPAQueryFactory jpaQueryFactory) {
this.jpaQueryFactory = jpaQueryFactory;
}
@Override
public List<BoardPagingResponse> findBoards(final Long pageSize, final Long id) {
return jpaQueryFactory
.select(Projections.constructor(BoardPagingResponse.class,
board.id.as("boardId"),
board.title))
.from(board)
.where(ltBoardId(id))
.orderBy(board.id.desc())
.limit(pageSize)
.fetch();
}
private BooleanExpression ltBoardId(final Long boardId) {
if (boardId == null) {
return null;
}
return board.id.lt(boardId);
}
}
위의 쿼리는 다음과 같다.
SELECT BOARD.id, BOARD.title
FROM BOARD
WHERE id < 마지막조회 ID
ORDER BY id DESC
LIMIT 페이지 사이즈
직전 조회 결과의 마지막 id를 입력으로 받아서 매번 이전 페이지 전체를 건너뛸 수 있다.
즉 매번 처음 페이지를 읽는 것과 동일한 성능을 가지게 된다는 장점이 있다.
하지만 페이징 버튼 방식을 사용할 수 없다는 단점이 있다.
커버링 인덱스
커버링 인덱스는 적용하지 않았지만, 만약 페이징 버튼이 꼭 필요하다면 적용할 가치가 있기에 작성하게 되었다.
커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 인덱스에서만 추출할 수 있는 인덱스를 말한다.
이를 통해 걸러낸 row의 id를 실제 select 절의 항목들을 빠르게 조회해 오는 방식이다.
예시 쿼리
SELECT *
FROM BOARD as b
JOIN (
SELECT id
FROM BOARD
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈
) as temp
ON temp.id = b.id
구체적으로 왜 커버링 인덱스가 더 빠른가?
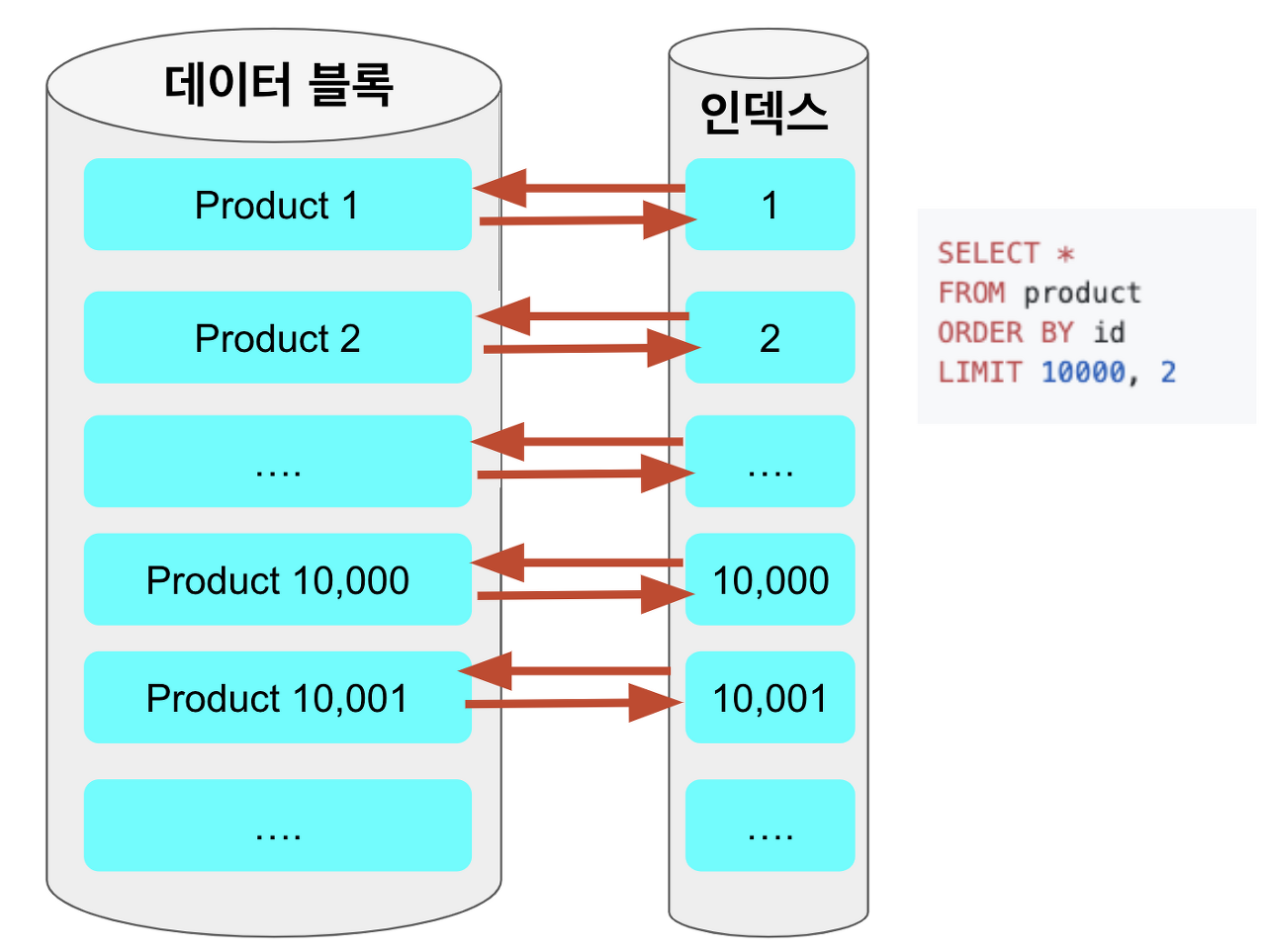
일반적으로 커버링 인덱스를 사용하지 않으면 위 그림처럼 offset, offset~limit을 수행할 때도 데이터 블록으로 접근을 하게 된다.
하지만 커버링 인덱스를 사용하면 아래와 같다.
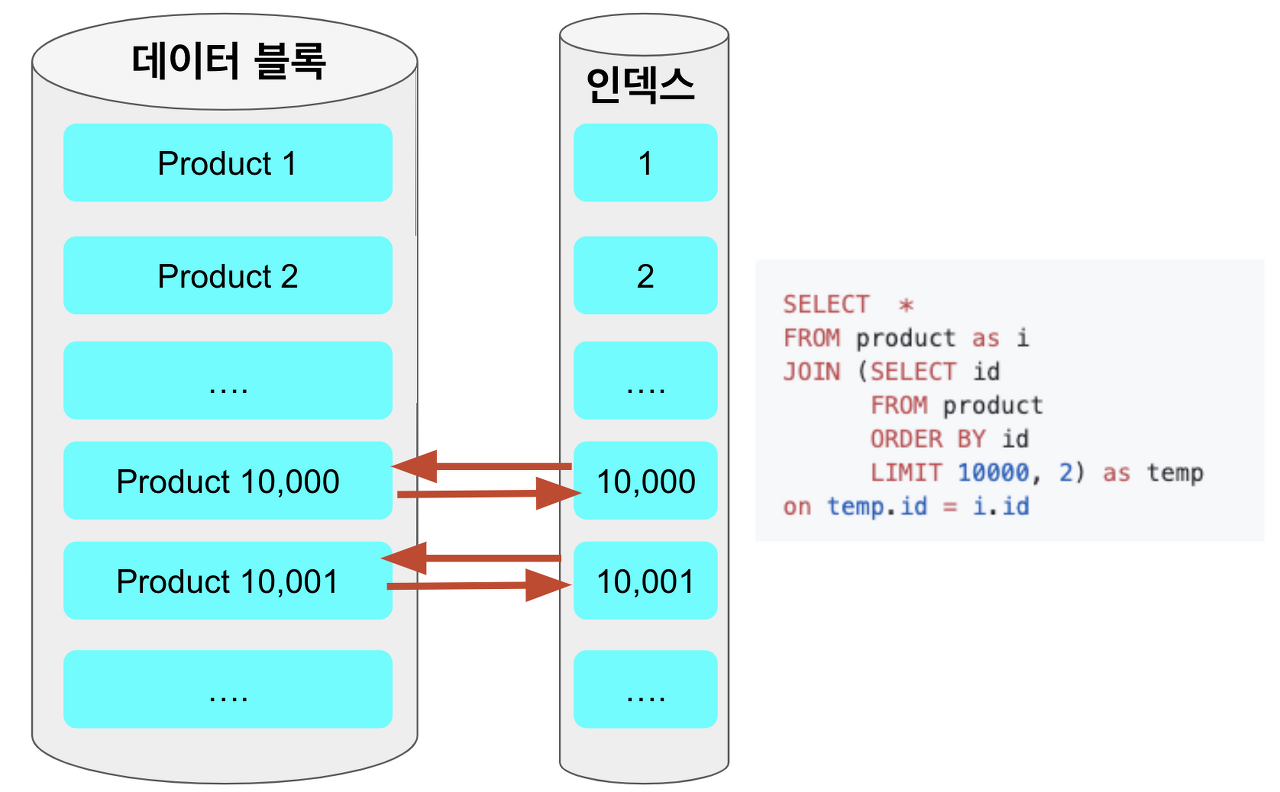
where, order by, offset ~ limit와 같은 검색을 데이터 블록 접근 없이 인덱스 검색으로 빠르게 처리하고, 걸러진 row들에 대해서만 데이터 블록에 접근하기에 성능의 이점을 얻게 된다.
우선 위와 같이 페이징 최적화에 대해 알아봤다.
이제 테스트를 통해 얼마나 빨라지는지 확인해 보자.
Test
이번 테스트는 커버링인덱스는 포함하지 않았다.
기존의 쿼리 vs NoOffset으로 진행하였다.
우선 스프링을 통해 테스트해 보자.
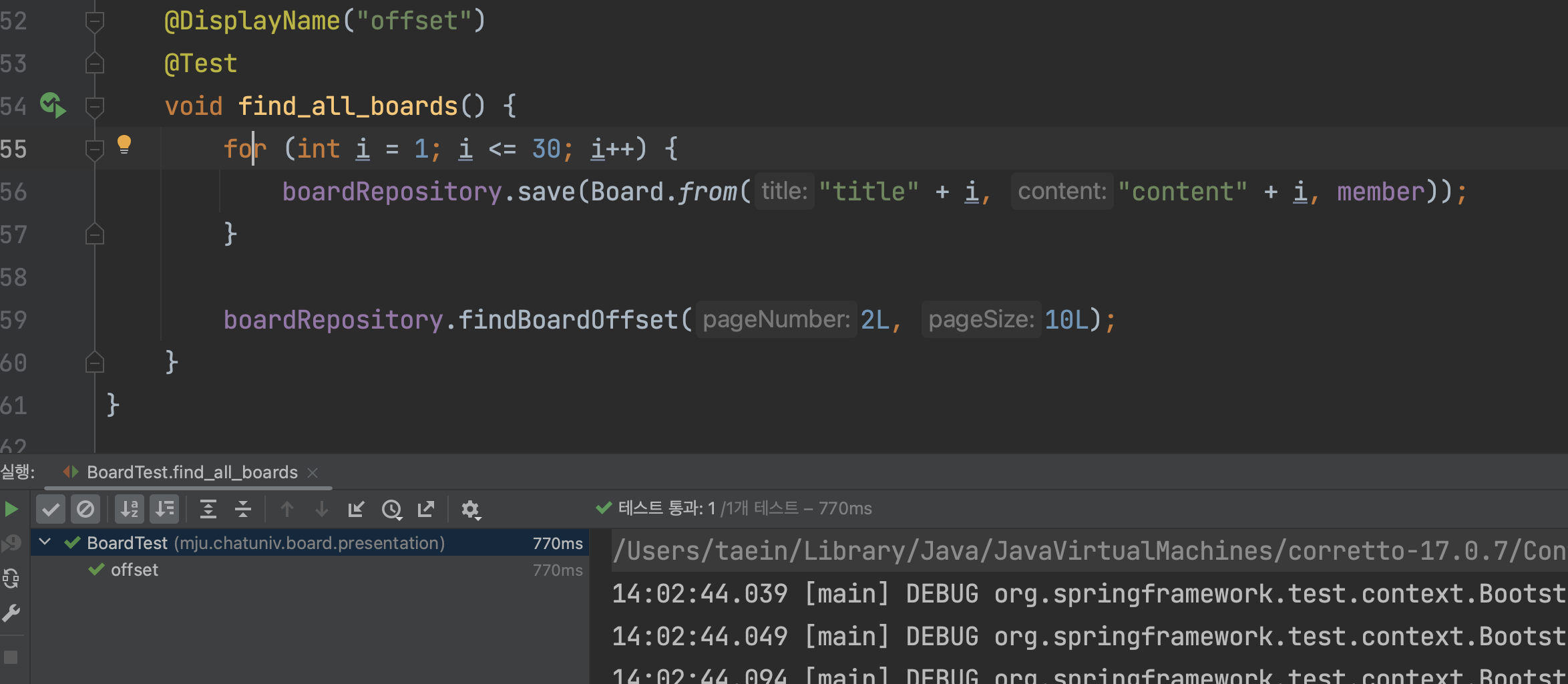
기존의 offset의 경우 770ms가 걸린다.
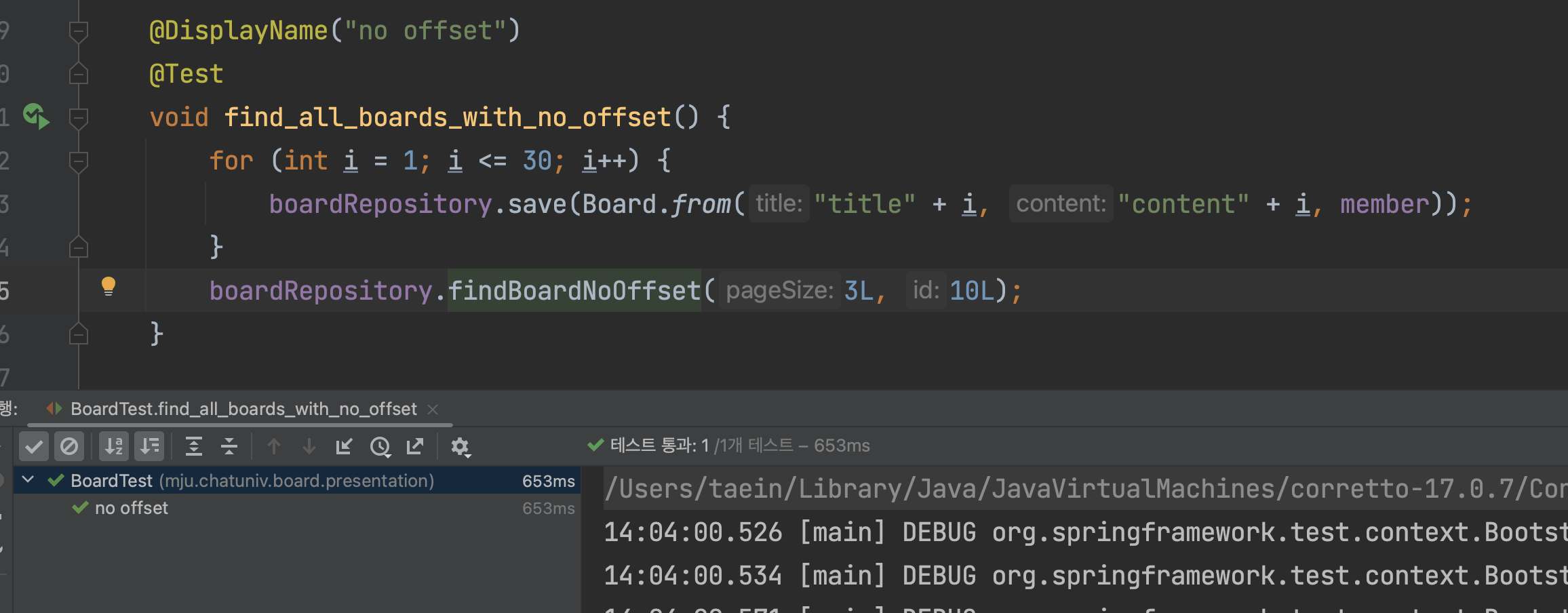
NoOffset의 경우 653ms가 걸린다.
데이터의 개수가 적어서 큰 차이를 알 수 없다.
db에 데이터를 100만 건 넣고 쿼리를 통해 비교해 보자.
우선 기존의 offset 방식이다.
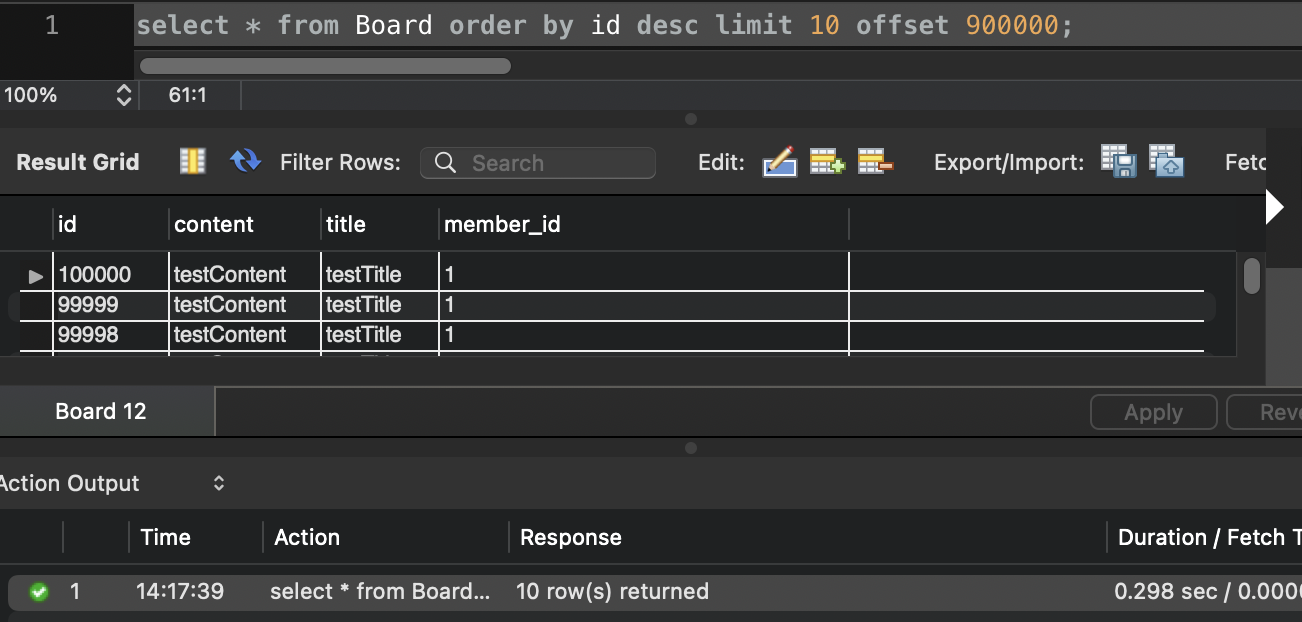
0.298 sec가 걸리게 된다.
이제 noOffset을 통해 테스트해 보자.
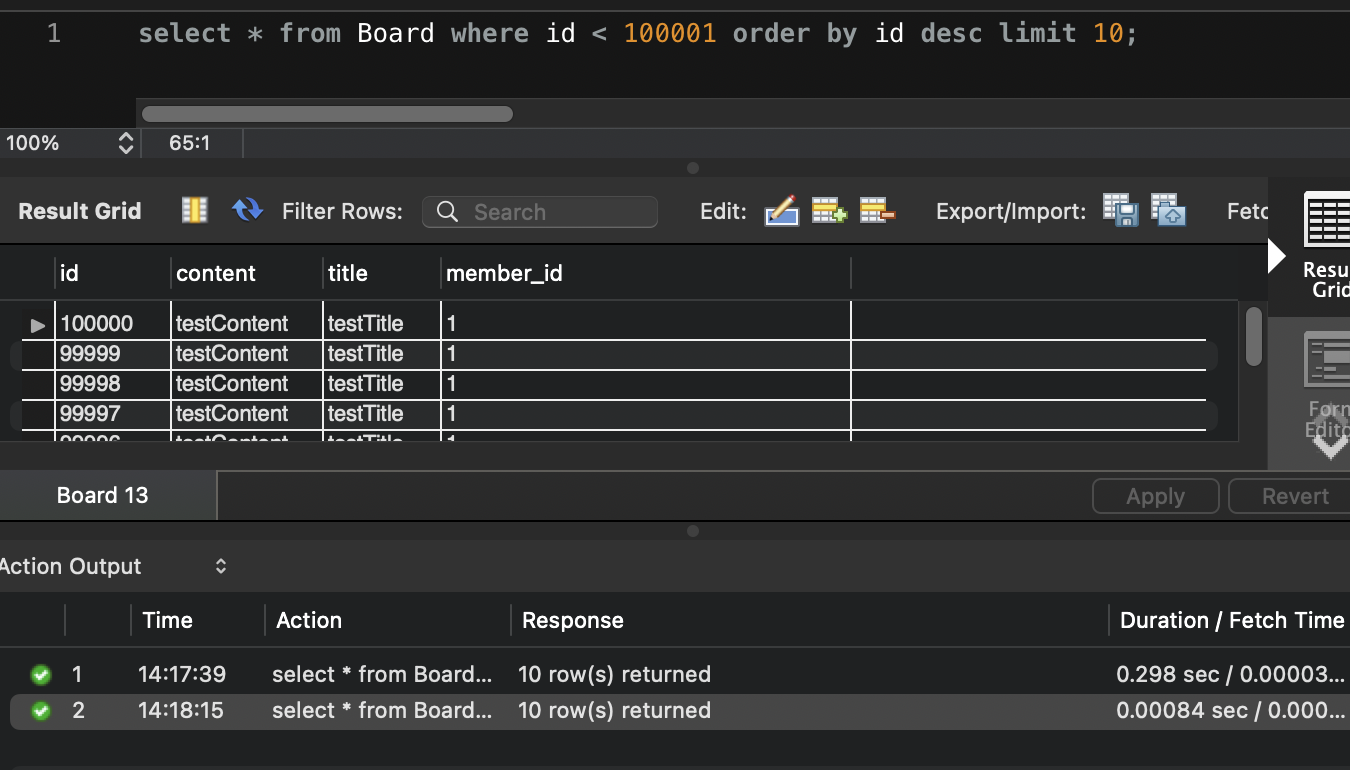
0.00084 sec가 걸리게 되었다.
무려 약 350배 이상의 속도 차이가 났다.
이는 데이터의 수가 증가하면 할 수 록 더 큰 차이가 발생하게 된다.
다른 시행착오
페이징 성능최적화를 하며 쿼리 dsl을 적용하였는데, 이때 경험하거나 실수한 부분을 기록하겠다.
Projections.fields
@Override
public List<BoardPagingResponse> findBoards(final Long pageSize, final Long id) {
return jpaQueryFactory
.select(Projections.fields(BoardPagingResponse.class,
board.id.as("boardId"),
board.title))
.from(board)
.where(ltBoardId(id))
.orderBy(board.id.desc())
.limit(pageSize)
.fetch();
}쿼리 부분이다.
처음에 DTO에서 기본 생성자를 private로 두고 진행하였는데, 에러가 발생하였다.
이를 통해 아래와 같은 사실을 알 수 있었다.
- Projections.fields는 특정 필드 값을 직접 매핑하여 DTO 객체를 생성하고 초기화할 수 있는 기능을 제공한다.
- 이 메서드는 Reflection을 사용하며, Reflection은 실행 중에 클래스의 정보를 분석하고 생성자, 필드, 메서드 등에 접근할 수 있는 기능을 제공한다.
- 따라서 다음과 같은 이유로 기본 생성자가 public으로 선언되어야 한다.
하지만 굳이 기본 생성자 없이 아래와 같이 DTO를 두고, Projections.constructor를 사용하는 것이 더 낫다고 생각하여 이를 수정했다.
@QueryProjection
public BoardPagingResponse(final Long boardId, final String title) {
this.boardId = boardId;
this.title = title;
}
@DataJpaTest
queryDSL을 추가하면서 기존의 테스트가 제대로 동작하지 않는 현상이 발생했었다.
우선 이를 요약하면 이 테스트는 리포지토리 테스트였다. 즉 @DataJpaTest를 통해 테스트를 진행하였다.
이때 중요한 점은 @DataJpaTest는 JPA관련 설정만 로드하고, 그 외의 컴포넌트나 설정은 로드하지 않는다는 것이다.
@DataJpaTest는 레포 어노테이션이 붙어있는 모든 클래스를 빈으로 등록해야 하는데, queryDSL이 추가되어서 아래의 설정을 직접 등록해주어야 했다.
@Configuration
public class AppConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory queryFactory() {
return new JPAQueryFactory(entityManager);
}
}
이를 해결하기 위해 간단하게 @Import(AppConfig.class)를 붙여서 해결할 수 있었다.
정리를 한다고 했는데, 사실 이외에도 많은 코드나 자세한 부분은 직접 코드를 보는 것이 편할 수 있다고 생각한다.
위 프로젝트에 대한 자세한 코드는 아래 깃허브 링크를 통해 확인할 수 있습니다.
https://github.com/kimtaesoo99/ChatUniv
GitHub - kimtaesoo99/ChatUniv: (2023~) GPT를 활용한 대학생들을 위한 서비스
(2023~) GPT를 활용한 대학생들을 위한 서비스. Contribute to kimtaesoo99/ChatUniv development by creating an account on GitHub.
github.com
'프로젝트 > ChatUniv' 카테고리의 다른 글
| [프로젝트] ChatUniv GPT 적용 (0) | 2023.08.26 |
|---|---|
| [프로젝트] ChatUniv Comment API, 동적 테스트 #4 (0) | 2023.07.30 |
| [프로젝트] ChatUniv Board API #3 (0) | 2023.07.16 |
| [프로젝트] ChatUniv Member API #2 (0) | 2023.07.16 |
| [프로젝트] ChatUniv 전반적인 설계 및 Auth구조 #1 (0) | 2023.07.04 |
페이징 최적화를 진행해 보았다.
페이징 최적화에는 크게 두 가지 방법이 있다.
NoOffset과 커버링 인덱스를 사용하는 방법이 존재한다.
이번에 프로젝트에서 게시글과 댓글의 페이징 최적화를 진행하였는데, 이 글은 게시글에 관해서만 작성할 예정이다.
일반적인 페이징 쿼리
기존의 코드는 아래와 같았다.
public interface BoardRepository extends JpaRepository<Board, Long> {
Page<Board> findAll(final Pageable pageable);
}
@Transactional(readOnly = true)
public BoardAllResponse findAllBoards(final Pageable pageable) {
Page<Board> sortedBoards = boardRepository.findAll(sortByIdWithDesc(pageable));
BoardPageInfo boardPageInfo = BoardPageInfo.from(sortedBoards);
List<BoardResponse> boards = sortedBoards.stream()
.map(BoardResponse::from)
.collect(collectingAndThen(toList(), Collections::unmodifiableList));
return BoardAllResponse.of(boards, boardPageInfo);
}
private PageRequest sortByIdWithDesc(final Pageable pageable) {
return PageRequest.of(pageable.getPageNumber(), pageable.getPageSize(), Sort.by(BOARD_ID).descending());
}
위의 쿼리는 다음과 같았다.
SELECT *
FROM BOARD
ORDER BY id DESC
OFFSET 페이지 번호
LIMIT 페이지 사이즈위 쿼리의 문제점은 OFFSET 번호가 뒤로 갈수록 느려진다는 점이다.
이유는 뒤페이지를 읽어야 한다면, 앞에 읽었던 행을 다시 읽어야 한다는 것 때문이다.
정작 앞의 부분은 필요로 하지 않기에 버리게 된다.
위를 해결하기 위해 선택한 방법은 NoOffset방식이다.
NoOffset
우선 NoOffset이란 페이지 번호가 없는 더 보기 방식이다.
그렇다면 왜 NoOffset을 사용할까?
NoOffset은 조회 시작 부분을 인덱스로 빠르게 찾아 매번 첫 페이지만을 읽도록 하는 방식이다.
이를 적용한 코드를 통해 알아보자.
public class BoardRepositoryCustomImpl implements BoardRepositoryCustom {
private final JPAQueryFactory jpaQueryFactory;
public BoardRepositoryCustomImpl(final JPAQueryFactory jpaQueryFactory) {
this.jpaQueryFactory = jpaQueryFactory;
}
@Override
public List<BoardPagingResponse> findBoards(final Long pageSize, final Long id) {
return jpaQueryFactory
.select(Projections.constructor(BoardPagingResponse.class,
board.id.as("boardId"),
board.title))
.from(board)
.where(ltBoardId(id))
.orderBy(board.id.desc())
.limit(pageSize)
.fetch();
}
private BooleanExpression ltBoardId(final Long boardId) {
if (boardId == null) {
return null;
}
return board.id.lt(boardId);
}
}
위의 쿼리는 다음과 같다.
SELECT BOARD.id, BOARD.title
FROM BOARD
WHERE id < 마지막조회 ID
ORDER BY id DESC
LIMIT 페이지 사이즈
직전 조회 결과의 마지막 id를 입력으로 받아서 매번 이전 페이지 전체를 건너뛸 수 있다.
즉 매번 처음 페이지를 읽는 것과 동일한 성능을 가지게 된다는 장점이 있다.
하지만 페이징 버튼 방식을 사용할 수 없다는 단점이 있다.
커버링 인덱스
커버링 인덱스는 적용하지 않았지만, 만약 페이징 버튼이 꼭 필요하다면 적용할 가치가 있기에 작성하게 되었다.
커버링 인덱스란, 쿼리를 충족시키는데 필요한 모든 데이터를 인덱스에서만 추출할 수 있는 인덱스를 말한다.
이를 통해 걸러낸 row의 id를 실제 select 절의 항목들을 빠르게 조회해 오는 방식이다.
예시 쿼리
SELECT *
FROM BOARD as b
JOIN (
SELECT id
FROM BOARD
WHERE 조건문
ORDER BY id DESC
OFFSET 페이지번호
LIMIT 페이지사이즈
) as temp
ON temp.id = b.id
구체적으로 왜 커버링 인덱스가 더 빠른가?
일반적으로 커버링 인덱스를 사용하지 않으면 위 그림처럼 offset, offset~limit을 수행할 때도 데이터 블록으로 접근을 하게 된다.
하지만 커버링 인덱스를 사용하면 아래와 같다.
where, order by, offset ~ limit와 같은 검색을 데이터 블록 접근 없이 인덱스 검색으로 빠르게 처리하고, 걸러진 row들에 대해서만 데이터 블록에 접근하기에 성능의 이점을 얻게 된다.
우선 위와 같이 페이징 최적화에 대해 알아봤다.
이제 테스트를 통해 얼마나 빨라지는지 확인해 보자.
Test
이번 테스트는 커버링인덱스는 포함하지 않았다.
기존의 쿼리 vs NoOffset으로 진행하였다.
우선 스프링을 통해 테스트해 보자.
기존의 offset의 경우 770ms가 걸린다.
NoOffset의 경우 653ms가 걸린다.
데이터의 개수가 적어서 큰 차이를 알 수 없다.
db에 데이터를 100만 건 넣고 쿼리를 통해 비교해 보자.
우선 기존의 offset 방식이다.
0.298 sec가 걸리게 된다.
이제 noOffset을 통해 테스트해 보자.
0.00084 sec가 걸리게 되었다.
무려 약 350배 이상의 속도 차이가 났다.
이는 데이터의 수가 증가하면 할 수 록 더 큰 차이가 발생하게 된다.
다른 시행착오
페이징 성능최적화를 하며 쿼리 dsl을 적용하였는데, 이때 경험하거나 실수한 부분을 기록하겠다.
Projections.fields
@Override
public List<BoardPagingResponse> findBoards(final Long pageSize, final Long id) {
return jpaQueryFactory
.select(Projections.fields(BoardPagingResponse.class,
board.id.as("boardId"),
board.title))
.from(board)
.where(ltBoardId(id))
.orderBy(board.id.desc())
.limit(pageSize)
.fetch();
}쿼리 부분이다.
처음에 DTO에서 기본 생성자를 private로 두고 진행하였는데, 에러가 발생하였다.
이를 통해 아래와 같은 사실을 알 수 있었다.
- Projections.fields는 특정 필드 값을 직접 매핑하여 DTO 객체를 생성하고 초기화할 수 있는 기능을 제공한다.
- 이 메서드는 Reflection을 사용하며, Reflection은 실행 중에 클래스의 정보를 분석하고 생성자, 필드, 메서드 등에 접근할 수 있는 기능을 제공한다.
- 따라서 다음과 같은 이유로 기본 생성자가 public으로 선언되어야 한다.
하지만 굳이 기본 생성자 없이 아래와 같이 DTO를 두고, Projections.constructor를 사용하는 것이 더 낫다고 생각하여 이를 수정했다.
@QueryProjection
public BoardPagingResponse(final Long boardId, final String title) {
this.boardId = boardId;
this.title = title;
}
@DataJpaTest
queryDSL을 추가하면서 기존의 테스트가 제대로 동작하지 않는 현상이 발생했었다.
우선 이를 요약하면 이 테스트는 리포지토리 테스트였다. 즉 @DataJpaTest를 통해 테스트를 진행하였다.
이때 중요한 점은 @DataJpaTest는 JPA관련 설정만 로드하고, 그 외의 컴포넌트나 설정은 로드하지 않는다는 것이다.
@DataJpaTest는 레포 어노테이션이 붙어있는 모든 클래스를 빈으로 등록해야 하는데, queryDSL이 추가되어서 아래의 설정을 직접 등록해주어야 했다.
@Configuration
public class AppConfig {
@PersistenceContext
private EntityManager entityManager;
@Bean
public JPAQueryFactory queryFactory() {
return new JPAQueryFactory(entityManager);
}
}
이를 해결하기 위해 간단하게 @Import(AppConfig.class)를 붙여서 해결할 수 있었다.
정리를 한다고 했는데, 사실 이외에도 많은 코드나 자세한 부분은 직접 코드를 보는 것이 편할 수 있다고 생각한다.
위 프로젝트에 대한 자세한 코드는 아래 깃허브 링크를 통해 확인할 수 있습니다.
https://github.com/kimtaesoo99/ChatUniv
GitHub - kimtaesoo99/ChatUniv: (2023~) GPT를 활용한 대학생들을 위한 서비스
(2023~) GPT를 활용한 대학생들을 위한 서비스. Contribute to kimtaesoo99/ChatUniv development by creating an account on GitHub.
github.com
'프로젝트 > ChatUniv' 카테고리의 다른 글
| [프로젝트] ChatUniv GPT 적용 (0) | 2023.08.26 |
|---|---|
| [프로젝트] ChatUniv Comment API, 동적 테스트 #4 (0) | 2023.07.30 |
| [프로젝트] ChatUniv Board API #3 (0) | 2023.07.16 |
| [프로젝트] ChatUniv Member API #2 (0) | 2023.07.16 |
| [프로젝트] ChatUniv 전반적인 설계 및 Auth구조 #1 (0) | 2023.07.04 |