
이번에는 재난 알리미라는 어플을 만들었다.
평소에 바쁜 일상 때문인지 나의 나태함 때문인지 글을 오랜만에 작성하게 되었다.
프로젝트 전체적인 정리, 핵심기능을 작성하려 한다.
재난 알리미가 무엇인가?

- 위와 같이 현재 존재하는 재난 알림은 나의 위치기반으로 한 재난 알림만 받을 수 있기에 지인의 정보도 얻을 수 있도록 하고 싶었다.
- AED나 대피소와 같은 위치 기반 조회 시스템이 부족하다고 생각했다.
- 인위재난의 경우 빠르게 알아채기 어렵다.
이러한 니즈를 해소하기 위해 개발을 시작했다.
서비스의 특징

Spring Security
스프링 시큐리티를 활용하여 로그인을 구현하였다.
Security Config
@Configuration
@EnableWebSecurity
@RequiredArgsConstructor
public class SecurityConfig {
private final JwtAuthenticationFilter jwtAuthenticationFilter;
private final ExceptionHandlerFilter exceptionHandlerFilter;
// CORS 설정
CorsConfigurationSource corsConfigurationSource() {
return request -> {
CorsConfiguration config = new CorsConfiguration();
config.setAllowedHeaders(Collections.singletonList("*"));
config.setAllowedMethods(Collections.singletonList("*"));
config.setAllowedOriginPatterns(Arrays.asList("http://localhost:3000", "https://i11a607.p.ssafy.io", "http://10.0.2.2:3000","https://mono-repo-practice.vercel.app/"));
config.setAllowCredentials(true);
return config;
};
}
// Password 인코딩 방식에 BCrypt 암호화 방식 사용
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public WebSecurityCustomizer webSecurityCustomizer() { // security를 적용하지 않을 리소스
return web -> web.ignoring()
// error endpoint를 열어줘야 함, favicon.ico 추가!
.requestMatchers("/error", "/favicon.ico","/swagger-ui/**","/swagger-resources/**","/v3/api-docs/**",
"/swagger-ui.html/**");
}
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
// CSRF 보호 기능 비활성화, 세션을 사용하지 않기때문에
.csrf((csrfConfig) ->
csrfConfig.disable()
)
// Clickjacking 공격을 방지하기 위한 X-Frame-Options 헤더 비활성화
// 캐시 제어 비활성화
.headers((headerConfig) ->
headerConfig.frameOptions(frameOptionsConfig ->
frameOptionsConfig.disable()
)
.cacheControl(cacheControl -> cacheControl.disable())
)
// session 사용 X 명시
.sessionManagement((sessionConfig) ->
sessionConfig.sessionCreationPolicy(SessionCreationPolicy.STATELESS)
)
.cors(corsConfigurer -> corsConfigurer.configurationSource(corsConfigurationSource()))
// HTTP 요청에 대한 보안 설정
.authorizeHttpRequests(authorizeRequests ->
authorizeRequests
// '/login', '/oauth2' 나머지 모든 요청은 인증된 사용자만 접근 가능
.requestMatchers("/register", "/login", "/register/duplicate","/reissue","/login/oauth", "/oauth2/**"
,"/login/oauth2/**", "/error", "login/oauth2/code/kakao","/swagger-ui/**"
,"/swagger-resources/**", "/v3/api-docs/**", "/fcm/test", "/sms/**", "/locations/**").permitAll()
// .requestMatchers("/**").permitAll()
// .requestMatchers("/admin").hasRole("ADMIN") // admin은 ADMIN 롤만
.anyRequest().authenticated()
)
.addFilterBefore(jwtAuthenticationFilter, UsernamePasswordAuthenticationFilter.class)
.addFilterBefore(exceptionHandlerFilter, JwtAuthenticationFilter.class);
return http.build();
}
}
Jwt
JwtAuthenticationFilter
/**
* OncePerRequestFilter : 요청당 한 번만 실행되어야 하는 작업 시 사용
* 모든 요청에 대해서 JWT를 검증함
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class JwtAuthenticationFilter extends OncePerRequestFilter {
private final JwtTokenProvider jwtTokenProvider;
private final AntPathMatcher antPathMatcher = new AntPathMatcher();
private static final List<String> EXCLUDE_URLS = Arrays.asList(
"/register", "/login", "/reissue", "/login/oauth", "/oauth2/**", "/login/oauth2/**", "/error",
"/login/oauth2/code/kakao", "/swagger-ui/**", "/swagger-resources/**", "/v3/api-docs/**", "/fcm/test",
"/register/duplicate", "/sms/**", "/locations/**"
);
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String requestURI = request.getRequestURI();
// 제외할 URI들
if (isExcluded(requestURI)) {
filterChain.doFilter(request, response);
return;
}
// 유효한 토큰인지 확인
String token = jwtTokenProvider.resolveToken(request);
if(token == null) {
filterChain.doFilter(request, response);
return;
}
if(!jwtTokenProvider.validateToken(token))
throw new CustomJwtException(ErrorCode.EXPIRED_JWT_TOKEN, "Access token이 만료됐습니다.");
// 토큰에서 userId와 role 추출
Claims payload = jwtTokenProvider.getPayload(token);
int userId = jwtTokenProvider.getUserIdFromPayload(payload);
Role role = jwtTokenProvider.getRoleFromPayload(payload);
// SecurityContextHolder에 토큰에서 추출한 userId와 role을 바탕으로 만든 authentication 넣기
UserDetails userDetails = new PrincipalDetails(userId, role);
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(userDetails, null, userDetails.getAuthorities());
authentication.setDetails(new WebAuthenticationDetailsSource().buildDetails(request));
SecurityContextHolder.getContext().setAuthentication(authentication);
filterChain.doFilter(request, response);
}
private boolean isExcluded(String requestURI) {
return EXCLUDE_URLS.stream().anyMatch(url -> antPathMatcher.match(url, requestURI));
}
}
JwtTokenProvider
/**
* Jwt Token util
*/
@Slf4j
@Component
public class JwtTokenProvider {
// todo: application.yml 변경공유 (secret key, expiration time)
private final SecretKey secretKey;
private final String userInfoSecretKey;
private final long accessTokenExpireTime;
private final long refreshTokenExpireTime;
public static final String TOKEN_PREFIX = "Bearer ";
public static final String HEADER_STRING = "Authorization";
private final AES256SecureUtil aes256SecureUtil;
private final Set<String> invalidatedTokens = new HashSet<>();
// todo: static 변수를 생성자를 통해 할당이 맞는지
public JwtTokenProvider(@Value("${spring.jwt.secret}") String secretKey,
@Value("${spring.jwt.user-info-secret}") String userInfoSecretKey,
@Value("${spring.jwt.access_expiration_time}") long accessTokenExpireTime,
@Value("${spring.jwt.refresh_expiration_time}")long refreshTokenExpireTime){
this.userInfoSecretKey = userInfoSecretKey;
this.secretKey = Keys.hmacShaKeyFor(Decoders.BASE64URL.decode(secretKey)); // secretKey도 일반 문자열이 아닌 암호화된 문자열로
this.aes256SecureUtil = new AES256SecureUtil(userInfoSecretKey);
this.accessTokenExpireTime = accessTokenExpireTime;
this.refreshTokenExpireTime = refreshTokenExpireTime;
}
/**
* accessToken의 내용으로 새로운 accessToken을 만듭니다.
* @param accessToken
* @return
*/
public String reissue(String accessToken) {
Claims payload = getPayload(accessToken);
Integer userId = getUserIdFromPayload(payload);
Role role = getRoleFromPayload(payload);
return createAccessToken(userId, role);
}
// token 발급
public JwtToken issue(int userId, Role role) {
return new JwtToken(createAccessToken(userId, role), createRefreshToken());
}
//access token 생성
public String createAccessToken(int userId, Role role){
//userId와 role은 민감한 정보이기 때문에 암호화해서 payload에 넣어야 한다.
Date expireationDate = new Date(System.currentTimeMillis() + accessTokenExpireTime);
String userIdEncrypt = aes256SecureUtil.encrypt(Integer.toString(userId), expireationDate.toString());
String userRoleEncrypt = aes256SecureUtil.encrypt(role.toString(), expireationDate.toString());
Claims claims = Jwts.claims()
.subject("UserInfo")
.add("userId", userIdEncrypt)
.add("role", userRoleEncrypt)
.issuedAt(new Date())
.expiration(new Date(System.currentTimeMillis() + accessTokenExpireTime)).build();
return Jwts.builder()
.header()
.keyId("KeyId")
.and()
.claims(claims)
.signWith(secretKey, Jwts.SIG.HS256)
.compact();
}
//refresh token 생성
public String createRefreshToken(){
Claims claims = Jwts.claims()
.issuedAt(new Date())
.expiration(new Date(System.currentTimeMillis() + refreshTokenExpireTime)).build();
return Jwts.builder()
.header()
.keyId("KeyId")
.and()
.claims(claims)
.signWith(secretKey, Jwts.SIG.HS256)
.compact();
}
// payload 추출
public Claims getPayload(final String token) {
try {
return Jwts.parser()
.verifyWith(secretKey)
.build()
.parseSignedClaims(token)
.getPayload();
} catch (ExpiredJwtException e) {
return e.getClaims();
}
}
// userId 추출. 복호화 해야 한다.
public int getUserIdFromPayload(final Claims claims) {
String userId = claims.get("userId", String.class);
return Integer.parseInt(aes256SecureUtil.decrypt(userId, claims.getExpiration().toString()));
}
// role 추출. 복호화 해야 한다.
public Role getRoleFromPayload(Claims claims) {
String userRole = claims.get("role", String.class);
return Role.valueOf(aes256SecureUtil.decrypt(userRole, claims.getExpiration().toString()));
}
/**
* JWT 토큰의 유효성을 검증
* @param token JWT 토큰
* @return 토큰이 유효하면 true, 그렇지 않으면 false
*/
public boolean validateToken(final String token) {
try {
//jwt가 위변조되지 않았는지 secretKey를 이용해 확인
Jws<Claims> claims = Jwts.parser()
.verifyWith(secretKey)
.build()
.parseSignedClaims(token);
return true;
} catch(SecurityException | MalformedJwtException e){
throw new CustomJwtException(ErrorCode.INVALID_JWT_TOKEN);
} catch (ExpiredJwtException e) {
//refreshToken의 만료 상황과 accessToken의 만료 상황을 구분하기 위해
//호출 클래스에서 예외 처리
return false;
} catch (UnsupportedJwtException e){
throw new CustomJwtException(ErrorCode.UNSUPPORTED_JWT_TOKEN);
} catch (IllegalArgumentException e){
e.printStackTrace();
throw new CustomJwtException(ErrorCode.ILLEGAL_JWT_TOKEN);
}
}
/**
* 요청 헤더에서 JWT 토큰 추출
* @param request HTTP 요청
* @return JWT 토큰
*/
public String resolveToken(HttpServletRequest request) {
String bearerToken = request.getHeader(HEADER_STRING)
if (bearerToken != null && bearerToken.startsWith(TOKEN_PREFIX)) {
return bearerToken.substring(7);
}
return null;
}
public String resolveToken(String bearerToken) {
if (bearerToken != null && bearerToken.startsWith(TOKEN_PREFIX)) {
return bearerToken.substring(7);
}
return null;
}
}
들었던 의문점
- SecurityContextHolder의 역할 (세션 없이 동작하는 경우)
Spring Security에서 SecurityContextHolder는 현재 실행 중인 스레드의 SecurityContext를 저장하는 역할을 한다. 이 SecurityContext는 현재 사용자의 인증 정보 (Authentication)를 포함하고 있다. 일반적으로는 이 SecurityContext가 세션과 연동되지만, 세션을 사용하지 않는 경우에도 SecurityContextHolder는 여전히 중요한 역할을 한다.
- 왜 필요한가?: SecurityContextHolder는 현재 요청을 처리하는 동안 인증된 사용자의 정보를 저장하고, 다른 보안 관련 로직에서 이 정보를 참조할 수 있도록 한다. 예를 들어, @PreAuthorize 같은 어노테이션을 사용하거나, 서비스 레이어에서 인증된 사용자의 정보를 가져올 때 SecurityContextHolder를 활용함.
- 세션 없이 어떻게 작동하는가?: 세션을 사용하지 않으면, SecurityContextHolder는 요청별로 SecurityContext를 관리한다. 즉, 요청이 들어올 때 JWT 토큰을 검증하고, SecurityContext에 인증 정보를 설정한 다음, 해당 요청이 끝나면 SecurityContext가 비워지거나 삭제된다. 따라서 세션을 사용하지 않더라도 매 요청마다 인증을 처리할 수 있다.
- SecurityContextHolder.getContext(). setAuthentication(authentication)에 대한 동작 방식
JwtAuthenticationFilter에서 SecurityContextHolder.getContext(). setAuthentication(authentication);를 호출하는 이유는, 현재 요청에 대한 인증 정보를 SecurityContext에 저장하기 위해서이다. 이 작업은 매 요청마다 반복되지만, 각 요청이 별도의 스레드에서 실행되므로 SecurityContextHolder에 저장된 인증 정보는 해당 요청이 끝날 때까지 해당 스레드에만 영향을 미친다.
- 매 요청마다 context가 쌓이는 작업인가?: 아니다. SecurityContext는 각 요청마다 새로 생성된다. 따라서 매 요청마다 인증 정보가 SecurityContext에 설정되고, 요청이 끝나면 SecurityContext가 비워지거나 폐기된다. 이는 세션을 사용하지 않는 경우에도 동일하게 작동함.
- JWT와 Refresh Token의 유효기간이 같게되면 Refresh Token은 의미가 있을까?
Ref와 JWT의 만료시간이 동일하다고 쳤을 때, Ref 와 JWT 가 동시에 생성되어서 동시에 만료된다 한들, 이 둘이 항상 동일하게 사용되는 게 아니다.
예를 들어 금융권에서 Ref 30분 JWT 30분 이렇게 만들어졌다고 가정하고 JWT의30분 중 약 25분 정도 소진되어 JWT의 만료가 가까워졌을 때, 남은 5분 사이에 서비스를 더 사용할지 이대로 종료시킬지 사용자가 반드시 확인하는 순간을 만들고, 이때 JWT 갱신을 택하게 되면, 남은 5분 내에 JWT를 갱신하기 위한 키로써 Ref의 유효 시간을 갖는다.
- Login 이후 JWT/Ref를 받은후, 다음 매 Req 마다 JWT와 Ref를 보내서 Ref로 만료일 파악하고 JWT로 인증처리하는 방식에 대한 고찰
동접자 1000만을 생각해 보면REST 1천만으로 서비스가 가능한기? - 대충 2천만이라 가정
전통적인 방식 기준으로 1 API는1 Req에 1 DB Conn 하던가? - 대충 4 DB 한다 치자.
그럼 Conn Pool 이 1천만 * 2 * 4
Req 2천만 + DB 8천만의 Conn 값이 있다. - 1억 Conn이다.
여기서 BE의BE의 1DB, 25% (2천만 정도 Conn)이라도 줄이려는 목적이다.
- JWT는 DB conn을 줄이려고 태어난 거다.
Ref로 매번 DB를 갔다 오는 것은 동작은 되지만, 그럼 또 DB Conn 이 1 늘어나는 문제는 해결되지 않는다.
AccessToken과 달라진 게 없이 굳이 JWT를 써야 하는가?
Server에서만Ref 만료일 확인하고, JWT로 인증하면 되는 것이다.
DB 다녀올 것 없이, 처음부터 JWT에 만료일 넣고, DB는 Ref를 갱신할 때만 접속하면 된다.
크롤링
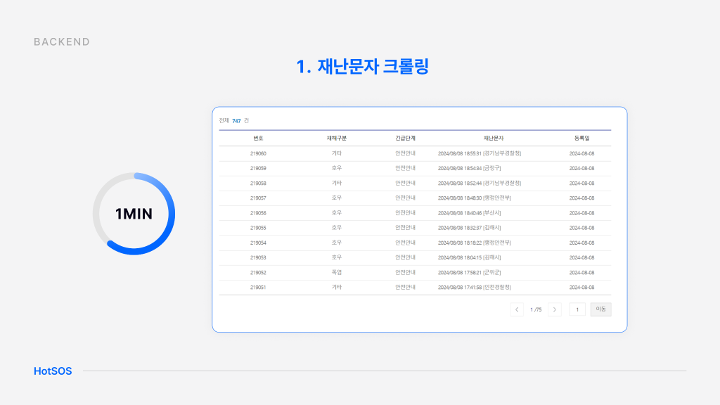
실시간 재난 문자 발생 여부를 파악하기 위해 1분마다 재난문자를 국민재난안전포털을 통해 크롤링해 저장하고 있다.
현재 1분 주기로 크롤링을 진행하지만 추후 대규모 API 시스템과 연동이 된다면 즉시 발송가능할 수 있도록 설계하였다.
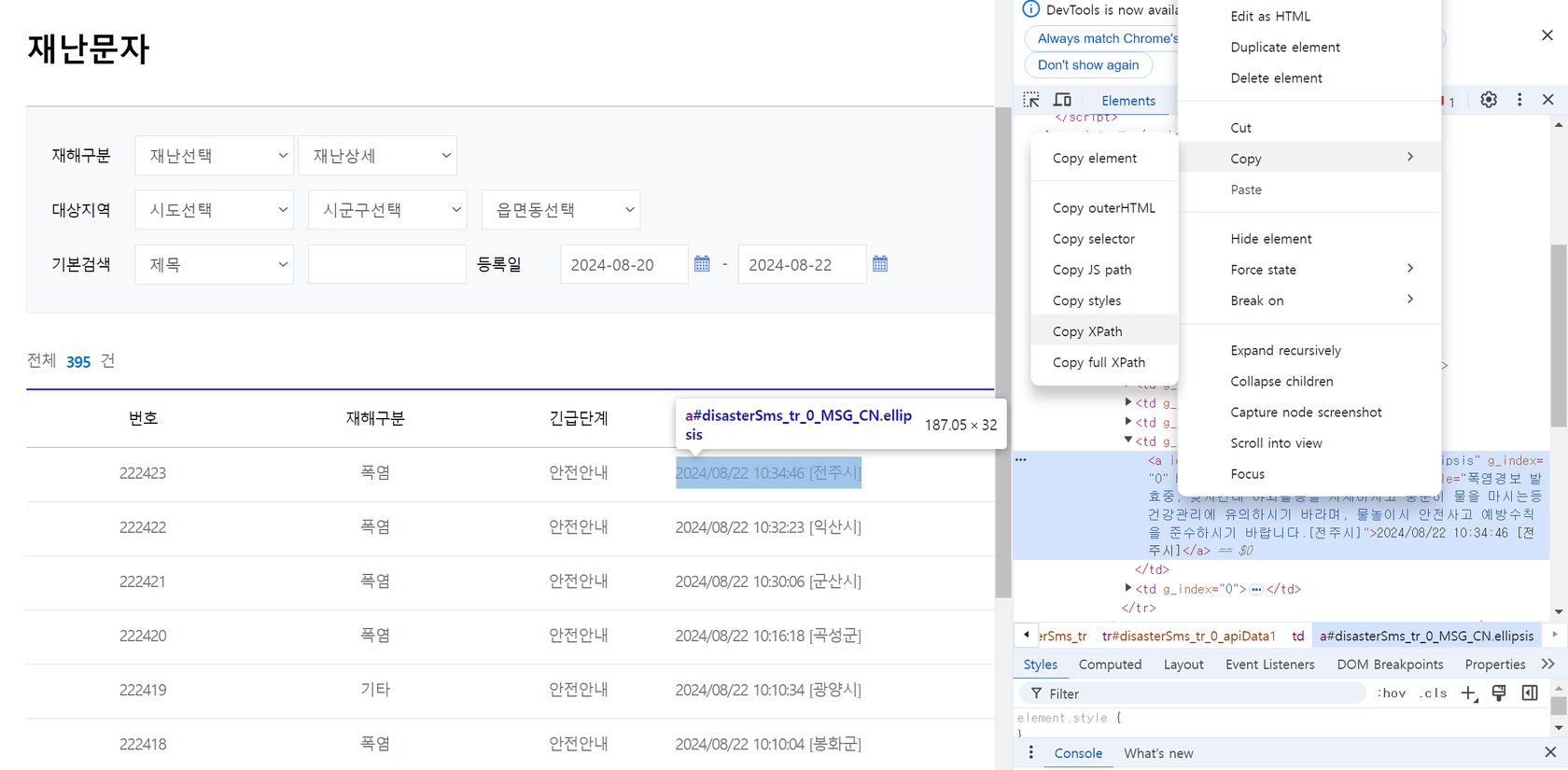
자동화된 프로그램을 사용해 웹사이트의 데이터를 수집하는 과정-> Selenium WebDriver를 사용
// 위 그림과 같이 내가 크롤링 하고 싶은 부분을 copy하면 되는데
// 개발자모드 -> 마우스포인터 -> copy -> XPath하고나서 아래와 같은 형식으로
// 붙여넣으면 됨
WebElement messageElement = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MSG_CN']"));
String message = messageElement.getText();
WebElement messageElement2 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MD101_SN']"));
String disasterNo = messageElement2.getText();
WebElement messageElement3 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_DSSTR_SE_NM']"));
String classification = messageElement3.getText();
Crawler
@Slf4j
@Component
public class Crawler {
public static final String WEB_SITE_ADDRESS = "https://www.safekorea.go.kr/idsiSFK/neo/sfk/cs/sfc/dis/disasterMsgList.jsp?menuSeq=679";
private static final int FETCH_WAIT_SECONDS = 10;
private static final int SCHEDULE_DELAY_MS = 60000;
private static int lastNo;
private final DisasterService disasterService;
public Crawler(final DisasterRepository disasterRepository, final DisasterService disasterService) {
Integer maxSerialNumber = disasterRepository.findMaxSerialNumber();
lastNo = maxSerialNumber != null ? maxSerialNumber : 1;
this.disasterService = disasterService;
}
@Scheduled(fixedDelay = SCHEDULE_DELAY_MS)
public void checkUpdateNews() {
WebDriverManager.chromedriver().setup();
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--no-sandbox");
options.addArguments("--disable-dev-shm-usage");
WebDriver driver = new ChromeDriver(options);
String baseUrl = WEB_SITE_ADDRESS;
driver.get(baseUrl);
try {
// 맨 위의 번호 요소를 찾습니다.
WebElement messageElement = driver.findElement(By.xpath("//*[@id='disasterSms_tr_0_MD101_SN']"));
int disasterNo = Integer.parseInt(messageElement.getText());
// 제일 최신값 비교해서 다르면 크롤링 시작, 같으면 작업 x
if (disasterNo != lastNo) {
List<CrawInfo> crawInfos = performCrawling(disasterNo - lastNo);
lastNo = disasterNo;
makeDisaster(crawInfos);
}
} catch (Exception e) {
System.out.println("An error occurred while fetching the disaster number: " + e.getMessage());
} finally {
driver.quit();
}
}
public void makeDisaster(List<CrawInfo> crawInfos) throws ParseException, IOException {
List<CrawInfo> result = new ArrayList<>();
// 아래 작업은 지역이름이 여러개인지 체크
for (CrawInfo crawInfo : crawInfos) {
String[] locationInfo = crawInfo.getLocation().split(", ");
if (locationInfo.length == 1) { // 정상인 경우 ex) 전북특별자치도 진안군
result.add(crawInfo);
} else { // 여러개인 경우 ex) 전북특별자치도 진안군, 전북특별자치도 장수군
String[] now = Arrays.stream(locationInfo)
.map(location -> {
String[] info = location.split(" ");
return info[0] + " " + info[1];
})
.distinct()
.toArray(String[]::new); // 여러개인데 중복일 경우 ex) 경기도 수원시 장안구, 경기도 수원시 권선구 -> 경기도 수원시
// 각각의 지역으로 추가
for (String info : now) {
result.add(CrawInfo.of(crawInfo, info));
}
}
}
disasterService.saveAll(result);
}
public List<CrawInfo> performCrawling(final int count) {
WebDriverManager.chromedriver().setup();
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--no-sandbox");
options.addArguments("--disable-dev-shm-usage");
options.addArguments("--disable-gpu");
options.addArguments("--ignore-ssl-errors=yes");
options.addArguments("--ignore-certificate-errors");
WebDriver driver = new ChromeDriver(options);
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(FETCH_WAIT_SECONDS));
String baseUrl = WEB_SITE_ADDRESS;
driver.get(baseUrl);
List<CrawInfo> crawInfos = new ArrayList<>();
int i = 0;
while (i < count) {
try {
WebElement messageElement = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MSG_CN']"));
String message = messageElement.getText();
WebElement messageElement2 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MD101_SN']"));
String disasterNo = messageElement2.getText();
WebElement messageElement3 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_DSSTR_SE_NM']"));
String classification = messageElement3.getText();
// log.info("재난문자 발생!!! {}", classification);
// if(classification.equals("기타")) continue;
WebElement messageElement4 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_EMRGNCY_STEP_NM']"));
String level = messageElement4.getText();
messageElement.click(); // 세부 정보를 보기 위해 클릭
// 세부 정보에서 메시지 내용 가져오기
wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//*[@id='msg_cn']")));
WebElement detailMessageElement = driver.findElement(By.xpath("//*[@id='msg_cn']"));
String detailMessage = detailMessageElement.getText();
WebElement locationElement = driver.findElement(By.xpath(" //*[@id=\"bbsDetail_0_cdate\"]"));
String location = locationElement.getText();
crawInfos.add(new CrawInfo(message, disasterNo, classification, level, detailMessage, location));
driver.navigate().back(); // 다시 목록으로 돌아가기
wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//*[@id='disasterSms_tr_" + (i + 1) + "_MSG_CN']")));
i++;
} catch (Exception e) {
// 더 이상 요소가 없을 때 예외가 발생하면 루프를 종료합니다.
break;
}
}
driver.quit();
return crawInfos;
}
}크롤링 사이트의 경우 번호 자체가 존재하여 새로운 글이 올라왔는지 확인이 가능하다.
이때 서버를 처음 킬 때 DB에 가장 큰 번호를 static변수로 가져와서 이후부터 업데이트 됐는지 판단할 때는 디비를 거칠 필요가 없어졌다.
GPT

우리 서비스의 경우 재난 문자가 오지 않는 상황이라 하더라도 게시판을 통해 실시간으로 긴급 상황을 파악할 수 있다.
하지만 욕설이나 개인정보와 같이 필터링이 필요한 정보까지 언급될 경우를 대비하고자 생성형 AI를 활용해 이를 적절히 처리하는 방법을 구현하였다.
또한 핫이슈 게시물이 등록될 경우 게시물 내용을 알람으로 보내는 것이 아니라, 게시물 내용을 AI를 활용해 사고 유형 및 심각성을 파악하도록 하고 어떤 상황에 대한 게시물인지에 대해 일관된 형식으로 알람을 보내도록 했다.
프롬프트 개선
처음에는 단순히 GPT에게 어떠한 작업을 해달라고 작성만 했었다.
하지만 이를 개선하기 위해 아래와 같은 방식을 사용했다.
- gpt에게 role(역할)을 부여해서 이전보다 정확도를 높임
- gpt api를 사용하면서 용도에 따라 System, User, Assistant를 구분해서 아래와 같은 형식으로 진행함
- System - ChatGPT에게 어떻게 행동을 할지 지정하는 기능
- Assistant 근데 System에 다 풀어서 적어도 어느 정도 잘되더라 - 이전 대화를 저장하고 연속성을 유지하기 위해 사용
- User - 우리가 하는 질문(prompt) 내용
FCM
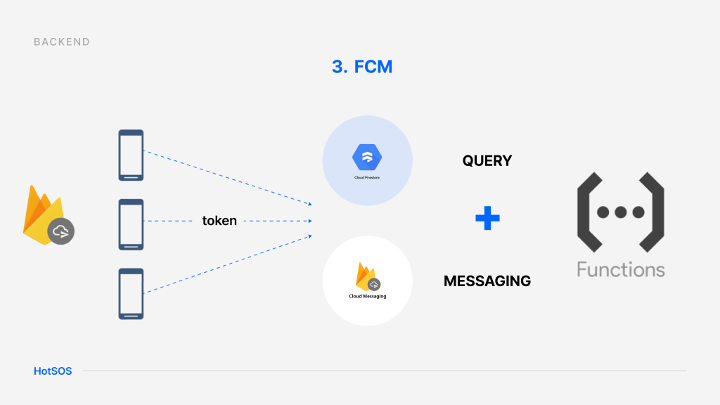
실시간 push 알림을 위해서 FCM(Firebase Cloud Messaging)을 선택함
알림을 구현하는 방식에는 Socket과 SSE 등이 있는데
FCM을 쓴 이유는 실시간성, 서버 안정성 측면에서 채택함
실시간성
우리 메인 서버가 알림을 보내는 로직을 수행 중인데 다른 작업 먼저 수행하는 상황이 발생하면 실시간성 알림이 보장되지 않음
실시간성을 보장하기 위해서는 지속적으로 연결상태를 유지해야 함
SSE, 소켓으로 구현하였을 때 얼마나 실시간성이 보장되고 지속적인 연결상태가 유지될지에 대한 의문점
복잡성
푸시 알림을 보낼 때에는 웹, 모바일 등의 플랫폼에 따라 다르게 보내줘야 함
⇒ 알림 기능의 실시간성을 보장하고 플랫폼에 종속되지 않기 위해 FCM을 사용함
FCM 동작원리
💡 FCM은 웹, 모바일 상황에서 device를 등록하고 추적해서 알림을 보내는 것이 아니다.
firebase 서버에서 발급된 fcmtoken을 고유키로 설정되면 푸시 알림은 fcmtoken을 기반으로 알림을 보내는 것이다.
- Firebase 서버에서 fcm을 보내기 위한 fcmtoken 발급 요청을 한다.
- Firebase 서버에서 fcmtoken을 발급받는다.
- Fcm 알림을 요청하면 발급된 fcmtoken을 목적지로 push 알림을 보낸다.
Firestore
위에서 FCM 동작수행을 위해서는 FCM토큰을 어딘가에 저장해야 한다.
이것을 어디에 저장할까 고민하다가 메인 DB인 mysql에 저장하면 되겠다는 생각을 했다.
하지만 fcm 알림을 보낼 때 서버와 DB 간의 통신을 최소화하고자 했고, firestore에 저장하는 것을 결정했다.
💡 Firestore VS Realtime DB 파이어베이스에는 db가 크게 두 가지 있음 우리 프로젝트에서는 복잡한 쿼리가 필요한 상황이라서 firestore를 사용하는 게 맞음 RealtimeDB는 단순쿼리와 필드구성이 복잡하지 않은 상황에서 사용하는 것이 적합함
Functions
💡Firebase용 Cloud Functions는 Firebase 기능과 HTTPS 요청에 의해 트리거 되는 이벤트에 응답하여 백엔드 코드를 자동으로 실행할 수 있는 서버리스 프레임워크입니다. 이 말을 쉽게 말하면 내가 firebase 기능을 사용할 로직을 메서드로 정의하고, firebase 서버에 배포하면, 배포된 url을 불러서 필요할 때 사용가능
functions를 사용하는 이유
functions를 사용하는 이유는 분리된 서버에서 파이어베이스 기능을 사용하기 위함이다.
분리된 서버에서 firebase기능을 사용하면 좋은 점은 우리 서버의 부하를 줄이고, 안정성 있게 fcm기능을 활용가능함
functions 기능으로 할 수 있는 것
예시를 들어서 설명하면 요청 시 body에 담아서 넘어온 userId, fcmToken, sido, gugun을 users 컬렉션에 token, sido, gugun, favoriteSido, favoriteGugun필드에 담는 로직임
exports.join = functions.https.onRequest(async (req, res) => {
const { userId, fcmToken, sido, gugun } = req.body;
if (!userId || !fcmToken || !sido || !gugun) {
console.error('Invalid request parameters:', { userId, fcmToken, sido, gugun });
return res.status(400).send('userId, fcmToken, sido, and gugun are required.');
}
try {
await admin.firestore()
.collection('users')
.doc(userId)
.set({
token: fcmToken,
sido: sido,
gugun: gugun,
favoriteSido: "",
favoriteGugun: "",
});
console.log('User data saved to Firestore:', { userId, sido, gugun });
return res.status(200).send('User data saved successfully');
} catch (error) {
console.error('Error saving user data to Firestore:', error);
return res.status(500).send('Error saving user data');
}
});이제 이렇게 만든 함수를 아래 명령어를 통해
firebase deploy --only functions

클라우드서버에 배포된 것을 확인하고 이제 내가 파이어베이스 db에 저장할 때 join url로 body만 잘 담아서 보내주면 됨
exports.sendBoardOwner = functions.https.onRequest(async (req, res) => {
const data = req.body;
const { alarmType, keyword, textList, title, content, userId, keyId, alarmId } = data;
// 필수 파라미터 확인
if (!userId || !title || !content) {
console.error('Invalid request parameters:', { userId, title, content });
return res.status(400).send('userId, title, and content are required.');
}
try {
console.log(`Received request to send notification to userId: ${userId}`);
// Firestore에서 userId가 일치하는 사용자 조회
const userRef = admin.firestore().collection('users').doc(userId);
const userDoc = await userRef.get();
if (!userDoc.exists) {
console.log(`No matching user found for userId: ${userId}`);
return res.status(404).send('No matching user found.');
}
const userData = userDoc.data();
if (!userData.token) {
console.log(`No FCM token found for userId: ${userId}`);
return res.status(404).send('No FCM token found for the specified user.');
}
// 알람 데이터를 사용자 문서의 alarms 하위 컬렉션에 저장
const alarmData = {
alarmType: alarmType || 'default', // 기본값 설정
keyword: keyword || '',
textList: textList || [],
title: title,
content: content,
timestamp: admin.firestore.FieldValue.serverTimestamp(),
keyId : keyId,
alarmId : alarmId,
isRead : 'N',
notificationType : 'personal'
};
try {
const userAlarmsRef = userRef.collection('alarms').doc();
await userAlarmsRef.set(alarmData);
console.log(`Alarm data saved for userId: ${userId}`);
} catch (error) {
console.error('Error saving alarm data:', error);
return res.status(500).send('Error saving alarm data: ' + error.message);
}
// 알람 데이터가 성공적으로 저장된 후 FCM 알림 전송
const token = userData.token;
const payload = {
notification: {
title: title,
body: content,
},
token: token,
};
const response = await admin.messaging().send(payload);
console.log('Successfully sent message:', response);
return res.status(200).send('Notification sent and alarm data saved successfully');
} catch (error) {
console.error('Error sending message:', error);
return res.status(500).send('Error sending message: ' + error.message);
}
});지금 이예시가 functions를 쓰는 이유임.
우선 sendBoardOwner 메서드는 댓글을 달 때마다 게시판 주인에게 알림을 보내기 위해 만든 메서드다.
크게 설명하면 users 컬렉션에서 게시판 작성자 알림 데이터를 저장하고, 게시판주인에게 알림을 보내라는 로직이다.
Token
알림 키워드 토큰화
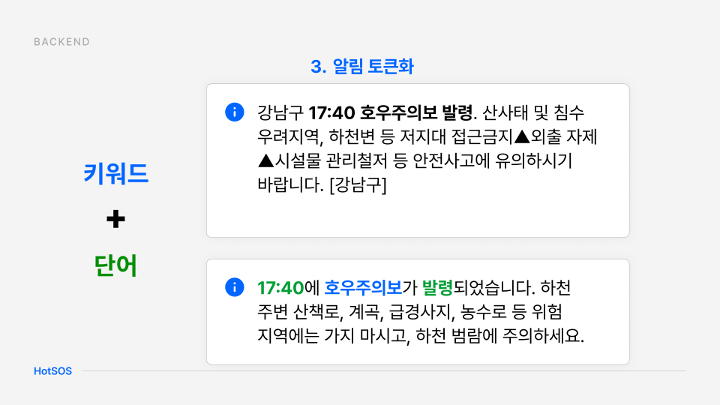
재난문자는 국가에서 제공되므로 이를 그대로 전달하면 중복 상황이 발생할 수 있다.
또한, 모든 알람을 데이터베이스에 중복 저장하는 것은 비효율적이다.
이를 해결하기 위해 저희는 재난 키워드를 추출해 템플릿 화하고, 일관된 형식으로 가독성을 높였다.
또한, 미리 카테고리화된 키워드를 사용해 불필요한 정보 저장을 줄였다.
구현 방법
- 키워드를 Enum으로 관리 (열대야, 소나기, 물놀이, 산사태 …)
- 토큰 추출 메서드 정의 (firebase에 저장되는 토큰)
- 토큰으로 알람 내용 만드는 메서드 정의 (사용자에게 보내지는 알람 내용)
- 키워드가 NONE이면 파이어베이스에 알람 내용 전체가 들어 있다고 가정
- 재난 문자 content에 키워드가 들어있는지 contains로 체크
AlarmKeyword
@Getter
public enum AlarmKeyword {
TROPICAL_NIGHT("열대야",
content -> List.of(),
tokens -> "오늘밤 열대야가 예상되오니, 적정실내온도설정, 미지근한 물 샤워, 가벼운 운동으로 건강관리에 유의하시기 바랍니다."),
SHOWER("소나기",
content -> {
// mm이 포함된 숫자나 범위를 추출하기 위한 정규 표현식
Pattern pattern = Pattern.compile("(약\\s*)?\\d+~?\\d*mm");
Matcher matcher = pattern.matcher(content);
String rainfallAmount = "";
while (matcher.find()) {
rainfallAmount = matcher.group();
}
return List.of(rainfallAmount);
},
tokens -> {
if (tokens.get(0).isEmpty()) {
return "소나기가 내릴 예정입니다. 산간계곡, 하천변 산책로 등 위험지역 출입을 자제하시기 바랍니다.";
}
return tokens.get(0) + "의 소나기가 내릴 예정입니다. 산간계곡, 하천변 산책로 등 위험지역 출입을 자제하시기 바랍니다.";
}),
HEAT_WAVE("폭염",
content -> List.of(),
tokens -> "매우 더운 날씨 지속 중입니다. 수분을 충분히 섭취하고, 현기증·메스꺼움 증상 시 즉시 휴식하세요."),
HEAVY_RAIN("집중호우",
content -> List.of(),
tokens -> "집중호우로 단시간에 급격한 하천 수위상승이 우려되니 하천변 산책로 등 저지대 침수지역 접근을 자제하여 주시기 바랍니다."),
HEAVY_RAIN_ADVISORY("호우주의보",
content -> {
if(content.contains("해제")){
return List.of("해제", content);
}
Pattern pattern = Pattern.compile("\\b\\d{2}:\\d{2}\\b");
Matcher matcher = pattern.matcher(content);
String time = "";
if (matcher.find()) {
time = matcher.group();
}
return List.of("발령",time);
},
tokens -> {
//해제
if(tokens.get(0).equals("해제")){
return tokens.get(1);
}
if(tokens.get(1).isEmpty()){
return "호우주의보가 발령되었습니다. 하천 주변 산책로, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 하천 범람에 주의하세요.";
}
return tokens.get(1) + "에 호우주의보가 발령되었습니다. 하천 주변 산책로, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 하천 범람에 주의하세요.";
}),
HEAVY_RAIN_WARNING("호우경보",
content -> {
Pattern pattern = Pattern.compile("\\b\\d{2}:\\d{2}\\b");
Matcher matcher = pattern.matcher(content);
String time = "";
if (matcher.find()) {
time = matcher.group();
}
return List.of(time);
},
tokens -> {
if(tokens.get(0).isEmpty()){
return "호우경보. 하천 주변, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 대피 권고를 받으면 즉시 대피하세요";
}
return tokens.get(0) + "에 호우경보. 하천 주변, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 대피 권고를 받으면 즉시 대피하세요";
});
private final String keyword; // 열대야, 소나기, 열사병, 폭염 등의 키워드
private final Function<String, List<String>> getTokensOp;
private final Function<List<String>, String> getContentOp;
//빠른 조회를 위한 해시맵
private static final Map<String, AlarmKeyword> keywordMap = Collections.unmodifiableMap(Stream.of(values())
.collect(Collectors.toMap(AlarmKeyword::getKeyword, Function.identity())));
AlarmKeyword(String keyword, Function<String, List<String>> getTokensOp, Function<List<String>, String> getContentOp) {
this.keyword = keyword;
this.getTokensOp = getTokensOp;
this.getContentOp = getContentOp;
}
public List<String> getTokens(String content) {
return getTokensOp.apply(content);
}
public String getContent(List<String> tokens) {
return getContentOp.apply(tokens);
}
public static AlarmKeyword getKeyword(String keyword) {
return keywordMap.get(keyword);
}
public static AlarmKeyword getKeyword(Disaster disaster) {
String msg = disaster.getMsg();
return Stream.of(values())
.filter(alarmKeyword -> msg.contains(alarmKeyword.getKeyword()))
.findFirst()
.orElse(null); // 메시지에 해당 키워드가 없으면 null 반환
}
}
N + 1
기존에 게시글을 수정하는 로직에서 디비에 여러 번 접근하는 문제가 발생했다.
이유는 @ManyToOne으로 연결된 entity들이 Lazy로딩으로 설정되어 있어서 실제 사용하는 순간에 디비에 접근하게 된다.
기존의 게시판 수정 코드(member, board, sido, gugun을 찾기 위해 디비에 접근 - select 4번)
@Override
public BoardResponse updateBoard(Integer id, BoardUpdateRequest request, Integer memberId) {
Board board = boardRepository.findById(id)
.orElseThrow(() -> new BoardNotFoundException("Board not found"));
if (!board.getMember().getId().equals(memberId)) {
throw new UnauthorizedBoardAccessException("You are not the owner of this board");
}
board.updateBoard(request.getTitle(), request.getContent());
Board updatedBoard = boardRepository.save(board);
return BoardResponse.from(updatedBoard);
}
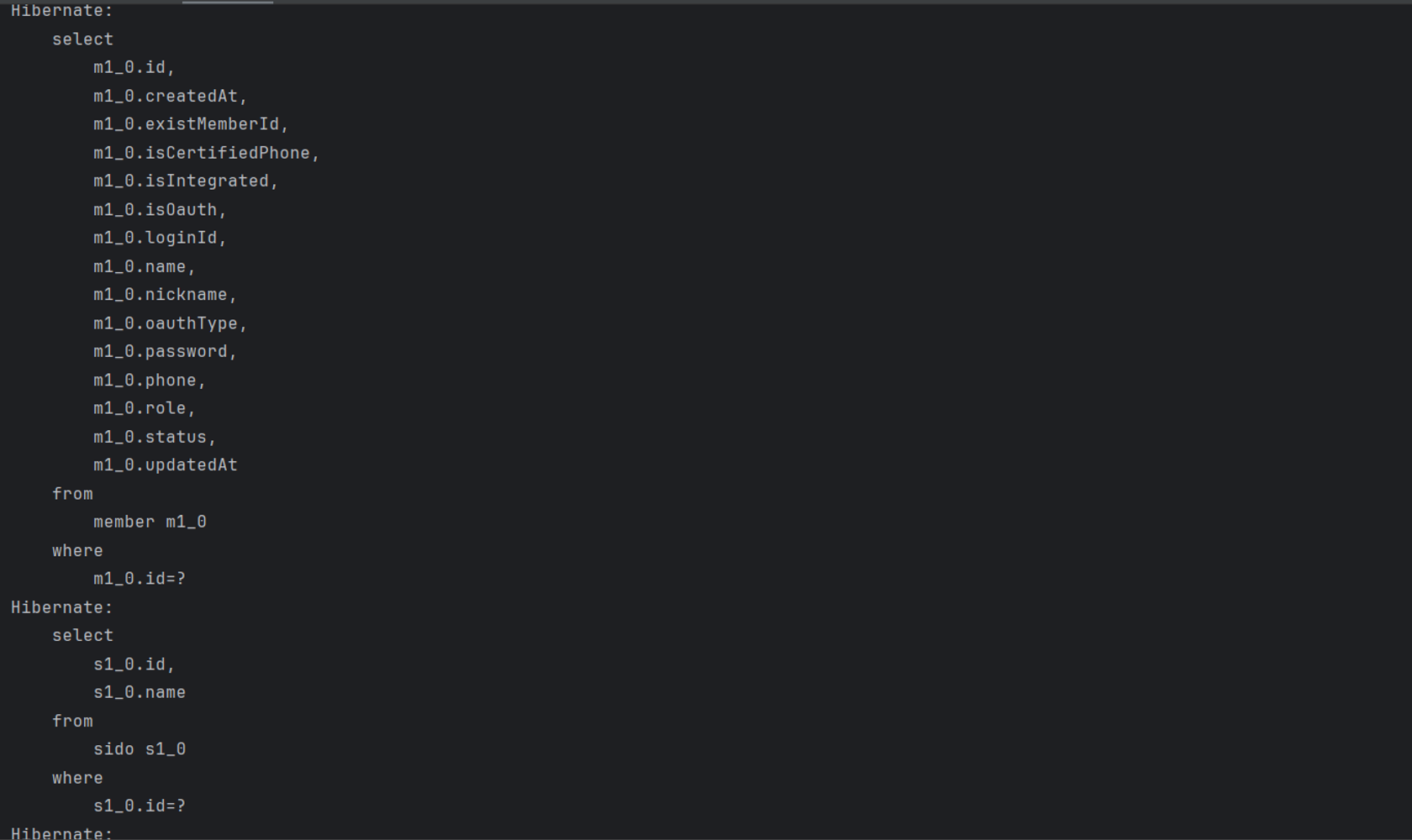
이걸 해결하고자 Fetch join을 사용함 -> Board를 가져올 때 필요한걸 같이 한 번에 가져옴
@Query("SELECT b FROM Board b " +
"JOIN FETCH b.member m " +
"JOIN FETCH b.sido s " +
"JOIN FETCH b.gugun g " +
"WHERE b.id = :id")
Optional<Board> findByIdWithMemberAndLocation(@Param("id") Integer id);
이후 로그를 보면 디비에 1번만 접근함
Hibernate:
select
b1_0.id,
b1_0.address,
b1_0.commentNum,
b1_0.content,
b1_0.count,
b1_0.createdAt,
b1_0.factCnt,
b1_0.gugun_id,
g1_0.id,
g1_0.name,
g1_0.sido_id,
b1_0.isAlarm,
b1_0.lat,
b1_0.lon,
b1_0.member_id,
m1_0.id,
m1_0.createdAt,
m1_0.existMemberId,
m1_0.isCertifiedPhone,
m1_0.isIntegrated,
m1_0.isOauth,
m1_0.loginId,
m1_0.name,
m1_0.nickname,
m1_0.oauthType,
m1_0.password,
m1_0.phone,
m1_0.role,
m1_0.status,
m1_0.updatedAt,
b1_0.reportCnt,
b1_0.sido_id,
s1_0.id,
s1_0.name,
b1_0.status,
b1_0.title,
b1_0.updatedAt,
b1_0.version
from
board b1_0
join
member m1_0
on m1_0.id=b1_0.member_id
join
sido s1_0
on s1_0.id=b1_0.sido_id
join
gugun g1_0
on g1_0.id=b1_0.gugun_id
where
b1_0.id=?
인덱스
- 인덱스는 데이터베이스에서 데이터를 빠르게 검색할 수 있도록 도와주는 자료 구조로 책의 목차처럼 특정 데이터의 위치를 빠르게 찾을 수 있게 함
- 하지만 단점으로 인덱스를 생성하고 유지하는데 추가적인 저장 공간이 필요하며 우리는 AED, 대피소 등의 데이터가 잘 안 변해서 상관이 없는데 데이터 삽입, 업데이트, 삭제 시 인덱스도 같이 갱신해야 하기 때문에 약간의 오버헤드가 발생할 수 있음
- 일반적으로 위도와 경도를 기준으로 인덱싱을 할 때 복합인덱스, 공간인덱스로 함
복합 인덱스
- 위도, 경도 두 개의 컬럼을 하나로 묶어서 인덱스 처리하는 것을 말함
ALTER TABLE aed ADD INDEX idx_lat_lon (lat, lon);
SHOW INDEX FROM aed;
--이후 위에 코드를 aed뿐만 아니라 civil_shelter, eo_shelter, et_shelter에 테이블명만 바꿔서 똑같이 적용해주면됨
ALTER TABLE civil_shelter ADD INDEX idx_lat_lon (lat, lon);
ALTER TABLE eo_shelter ADD INDEX idx_lat_lon (lat, lon);
ALTER TABLE et_shelter ADD INDEX idx_lat_lon (lat, lon);
인덱스를 적용한 부분이 위도, 경도를 기준으로 함
동시성 제어
대규모 트래픽이 몰리는 어플 특성상 동시성 이슈가 반드시 발생한다고 생각했음.
일단 동시성 제어를 위해 게시판 조회 시 조회수가 증가하는 로직을 단순히 실행해 봄
원격에서 1000번 요청을 보냄

1번 글에 대한 조회수가 204로 됨
이를 비관적 락을 적용함


2번 글에 대한 조회수가 1000으로 알맞게 나옴
이후 낙관적 락도 적용해 봄

비관적 락
- 장점
- Race Condition이 빈번하게 일어난다면 낙관적 락보다 성능이 좋다.
- DB 단의 Lock을 통해서 동시성을 제어하기 때문에 확실하게 데이터 정합성이 보장된다.
- 단점
- DB 단의 Lock을 설정하기 때문에 한 트랜잭션 작업이 정상적으로 끝나지 않으면 다른 트랜잭션 작업들이 대기해야 하므로 성능이 감소할 수 있다.
낙관적 락
- 장점
- DB 단에서 별도의 Lock을 설정하지 않기 때문에 하나의 트랜잭션 작업이 길어질 때 다른 작업이 영향받지 않아서 성능이 좋을 수 있다.
- 단점
- 버전이 맞지 않아서 예외가 발생할 때 재시도 로직을 구현해야 한다.
- 버전이 맞지 않는 일이 여러 번 발생한다면 재시도를 여러 번 거칠 것이기 때문에 성능이 좋지 않다.
서버 테스트
- 스트레스 테스트와 부하 테스트 차이
1. 대규모 부하 테스트 (Load Testing)
- 대규모 부하 테스트의 주목적은 시스템이 예상되는 최대 부하(예: 최대 사용자 수, 트랜잭션 수)에서도 안정적으로 동작하는지를 확인하는 것이다.
- 시스템의 성능, 응답 시간, 처리량 등을 평가하여 시스템이 정상적으로 운영될 수 있는 한계를 파악한다.
방법:
- 예상되는 실제 운영 환경의 부하 조건을 시뮬레이션
- 일정한 부하를 장기간 유지하여 시스템의 안정성을 평가함.
- 예: 특정 웹 애플리케이션이 1,000명의 동시 사용자를 처리할 수 있는지 테스트.
결과:
- 시스템이 최대 부하에서도 정상적으로 작동하는지 확인.
- 성능 병목 지점과 응답 시간, 처리량 등의 성능 지표를 분석.
2. 스트레스 테스트 (Stress Testing)
- 스트레스 테스트의 주목적은 시스템의 한계를 넘어서 극한 상황에서 시스템이 어떻게 반응하는지 평가하는 것.
- 시스템이 얼마나 많은 부하를 견딜 수 있는지, 그리고 실패 시 어떻게 회복하는지를 확인한다.
방법:
- 시스템의 최대 용량을 초과하는 부하를 가하여 시스템이 언제, 어떻게 실패하는지 관찰한다
- 예를 들어, 점진적으로 부하를 증가시켜 시스템의 한계점까지 도달하게 한다.
- 예상치 못한 상황(예: 네트워크 장애, 서버 다운)에서도 시스템의 회복 능력을 테스트한다.
결과:
- 시스템의 최대 용량과 한계를 파악.
- 시스템의 강인성(resilience)과 안정성, 그리고 장애 발생 시 복구 능력을 평가.
비교 요약특징 대규모 부하 테스트 스트레스 테스트
| 목적 | 최대 부하에서의 안정성 평가 | 시스템 한계와 회복 능력 평가 |
| 방법 | 실제 운영 환경의 최대 부하 시뮬레이션 | 한계점을 초과하는 극한 상황 시뮬레이션 |
| 결과 | 성능 병목, 응답 시간, 처리량 분석 | 시스템의 최대 용량, 실패 지점, 회복 능력 분석 |
| 부하 수준 | 예상 최대 부하 수준 | 예상 최대 부하를 초과하는 수준 |
| 시스템 반응 | 정상 운영 확인 | 실패와 회복 과정 관찰 |
결론
- 대규모 부하 테스트와 스트레스 테스트는 서로 보완적인 성격을 지니며, 모두 중요한 성능 평가 방법이다. 대규모 부하 테스트는 시스템이 일상적인 최대 부하에서도 안정적으로 동작하는지를 확인하는 반면, 스트레스 테스트는 시스템의 한계를 넘어서는 부하에서 시스템이 어떻게 반응하고 회복하는지를 평가한다. 이 두 가지 테스트를 모두 수행함으로써 시스템의 전반적인 성능과 안정성을 더욱 철저히 평가할 수 있다.
왜 아틀러리인가?
아틀러리(Artillery)
- 간단한 설정: YAML 또는 JSON 파일을 통해 쉽게 설정할 수 있으며, 사용자 친화적인 설정 방식이다.
- Node.js 기반: 비동기 특성을 활용하여 고성능 테스트를 지원한다.
- 실시간 분석: 테스트 도중 실시간으로 결과를 모니터링하고 분석할 수 있다.
- 분산 테스트: 여러 노드에서 동시에 테스트를 수행할 수 있어 대규모 부하를 시뮬레이션하기 용이하다.
적합한 테스트 유형:
- 스트레스 테스트: 아틀러리는 설정이 간단하고, 고성능 분산 테스트를 지원하므로 시스템의 한계를 초과하는 극한 상황을 시뮬레이션하는 데 적합하다.
- 부하 테스트: 물론 아틀러리도 부하 테스트를 잘 수행할 수 있으며, 특히 간단하고 빠르게 설정이 가능하다는 장점이 있다.
JMeter
- 다양한 프로토콜 지원: HTTP, FTP, JDBC, LDAP 등 매우 다양한 프로토콜을 지원하여 다양한 유형의 애플리케이션에 대해 테스트를 수행할 수 있다.
- 풍부한 기능: 다양한 플러그인과 스크립트 언어(Groovy, Beanshell)를 사용하여 확장 가능하다.
- 분산 테스트: 초기부터 분산 테스트 기능을 지원하며, 마스터-슬레이브 아키텍처를 통해 대규모 부하를 시뮬레이션할 수 있다.
- GUI 지원: 직관적인 GUI를 통해 테스트 계획을 쉽게 작성하고 실행할 수 있다.
적합한 테스트 유형:
- 부하 테스트: JMeter는 다양한 프로토콜과 복잡한 시나리오를 지원하므로, 실제 운영 환경을 정밀하게 시뮬레이션하여 시스템의 성능을 평가하는 데 매우 적합하다.
- 스트레스 테스트: JMeter도 스트레스 테스트를 수행할 수 있지만, 설정과 관리가 다소 복잡할 수 있다. 그러나 복잡한 시나리오를 지원하는 데 강점이 있다.
결론
아틀러리는 간단한 설정과 고성능 분산 테스트를 통해 빠르고 효율적으로 스트레스 테스트를 수행하는 데 적합하다. 사용이 간편하고, 실시간 분석 기능이 있어 시스템의 한계를 쉽게 파악할 수 있다.
JMeter는 다양한 프로토콜과 복잡한 시나리오를 지원하여 부하 테스트에 매우 적합하다. GUI 지원과 풍부한 기능 덕분에 실제 운영 환경을 정밀하게 시뮬레이션하고, 시스템의 성능을 전반적으로 평가하는 데 강력한 도구이다.
설치
npm install -g artillery@latest
npm install -g artillery@canary
npx artillery dino
artillery version
실행 방법
{
"config": {
"target": "원하는 주소",
"phases": [
{
"duration": 60,
"arrivalRate": 30
}
],
"defaults": {
"headers": {
"authorization": "access token"
}
}
},
"scenarios": [
{
"name" : "test",
"flow": [
{
"get": {
"url": "url"
}
}
]
}
]
}
테스트 결과
Nginx를 통한 서버 다운 개선
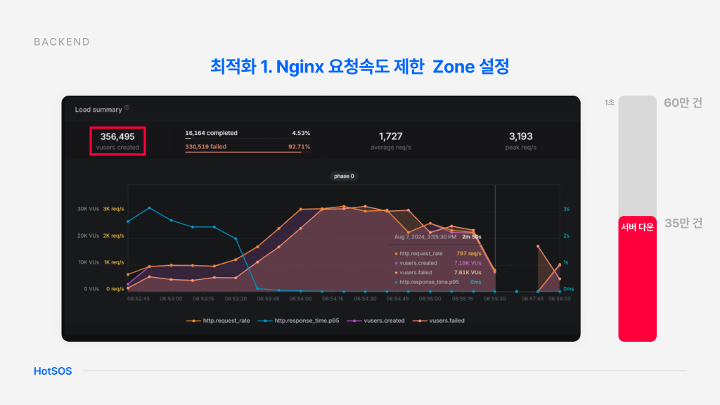
최적화를 위한 첫 번째 방법으로 niginx 요청 속도 제한 구역을 설정해 최대 요청 수를 제한했다.
최적화 이전에는 앞서 말씀드린 것과 같이 35만 건 이상의 요청이 들어오면 서버가 감당하지 못하고 다운되어 버린다.
user nginx;
worker_processes auto; # 서버의 CPU 코어 수에 맞게 자동 설정
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024; # 동시 연결 수 증가
multi_accept on; # 모든 새 연결을 동시에 수락
}
http {
# 요청 속도 제한을 위한 zone 설정
limit_req_zone $binary_remote_addr zone=one:10m rate=1000r/s;
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
include /etc/nginx/conf.d/*.conf;
}
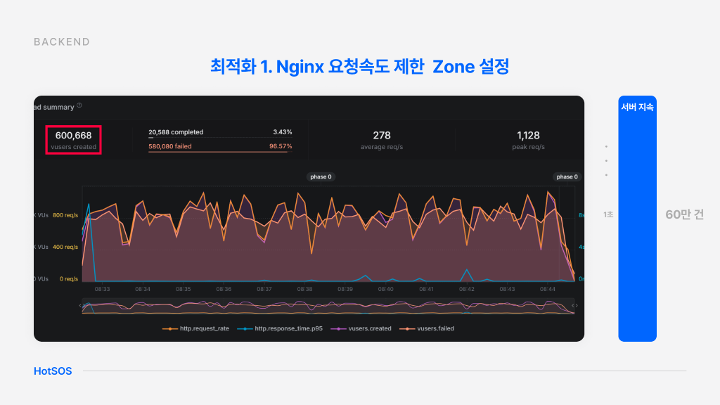
그러나 최적화 이후에는 60만 건의 요청까지 수용할 수 있으며 서버가 다운되지 않고 유지된다는 결과를 얻을 수 있었다.
이를 통해 대규모 트래픽이 발생해도 서비스를 지속할 수 있다는 것을 보장할 수 있다.
인덱스를 적용한 성능 개선
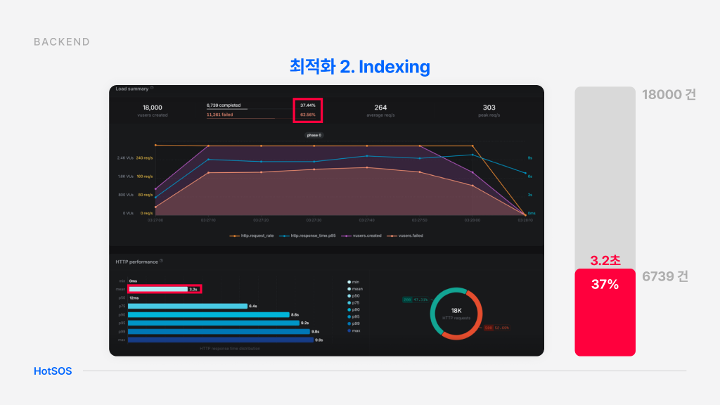
다음은 사용자에게 빠른 데이터를 제공하기 위해 복합 Indexing을 적용했다.
Indexing 적용 전의 경우 요청에 대한 응답을 생성하는 데 평균적으로 3.2초가 걸렸고 응답 성공률은 37%에 그침
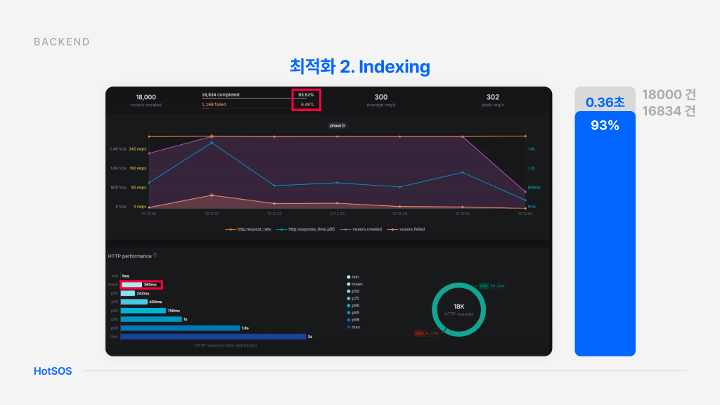
적용 후에는 평균 0.36초가 걸리며 응답 성공률 또한 93%로 현저하게 향상된 것을 보실 수 있습니다.
이를 통해 저희의 최적화 방법으로 데이터에 빠르게 접근하여 사용자에게 신속한 응답을 할 수 있다는 것을 확인할 수 있었습니다.
이유는 이전에는 요청 처리 과정이 길어서 스레드풀에서 할당한 자원을 모두 다 쓰면 다음 요청은 기다리다가 timeout이 발생해서 실패하는데 지금은 빠른 처리로 인해 timeout이 발생하지 않음.
Nginx Dynamic Caching을 통한 최적화
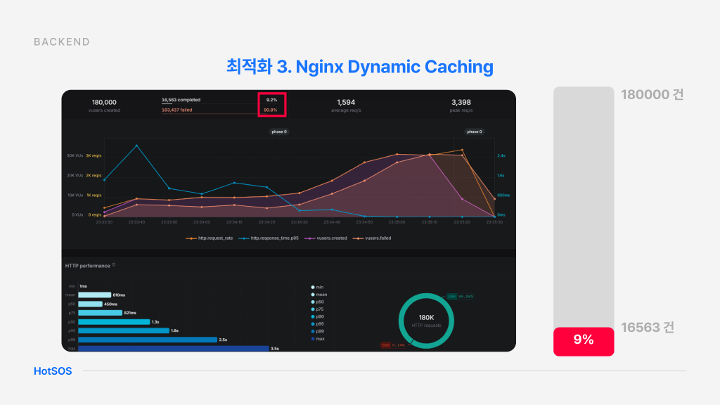
기존에 9%만 성공하는 것을 볼 수 있음
# /api/location 경로는 캐싱 처리
location /api/locations/ {
proxy_pass http://hotsos-be:8082/locations/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Prefix /api;
# 캐싱 설정
proxy_cache my_cache;
proxy_cache_valid 200 1h; # 200 OK 응답을 1시간 동안 캐시
# 타임아웃 설정
proxy_connect_timeout 300;
proxy_send_timeout 300;
proxy_read_timeout 300;
# 특정 조건에서 캐시를 무효화
set $bypass_cache 0;
# 캐시 무효화 조건
if ($http_cache_control = "no-cache") {
set $bypass_cache 1;
}
# CORS 설정
# add_header 'Access-Control-Allow-Origin' '*';
# add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, DELETE, PUT';
# add_header 'Access-Control-Allow-Headers' 'Origin, Authorization, Accept, Content-Type, X-Requested-With';
# add_header 'Access-Control-Allow-Credentials' 'true';
# wss(web-socket) 설정
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
http
// CSRF 보호 기능 비활성화, 세션을 사용하지 않기때문에
.csrf((csrfConfig) ->
csrfConfig.disable()
)
// Clickjacking 공격을 방지하기 위한 X-Frame-Options 헤더 비활성화
// 캐시 제어 비활성화
.headers((headerConfig) ->
headerConfig.frameOptions(frameOptionsConfig ->
frameOptionsConfig.disable()
)
.cacheControl(cacheControl -> cacheControl.disable())
)
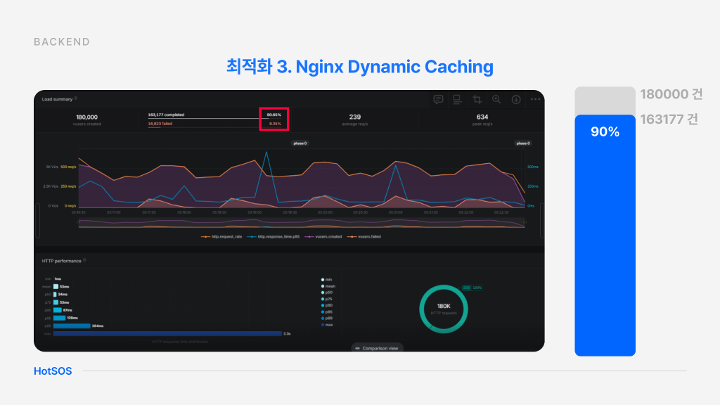
90% 까지 성공하는 것을 볼 수 있음
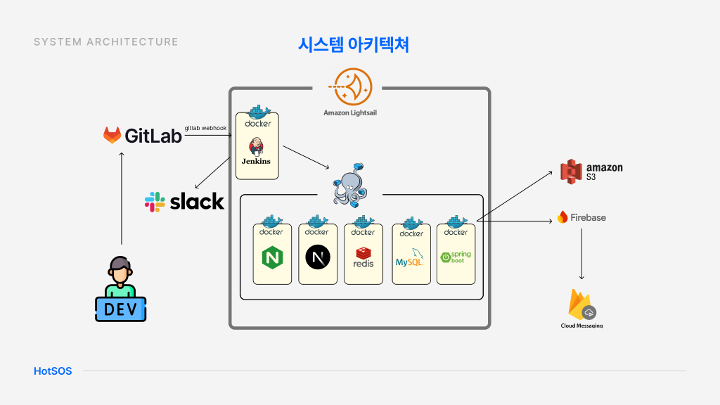
아키텍처
서비스 화면
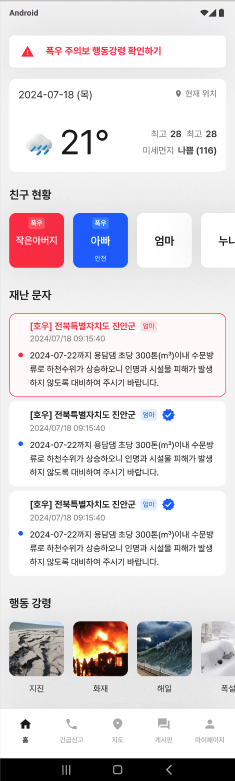
- 홈 화면에서는 현재 위치 기반 날씨 정보 및 친구들의 안전 상태를 확인할 수 있음
- 안전상태의 경우 친구들이 각자 설정할 수 있음(하루단위로 레디스를 사용)
- 여러 친구들의 재난 문자를 볼 수 있음(각자 실시간 위치 기반 GPS)
- 각 재난시 행동 강령을 볼 수 있음
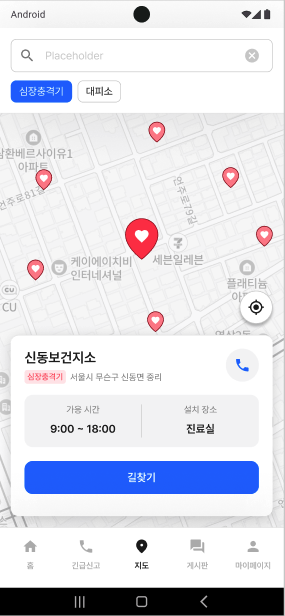
- AED와 대피소를 현재 위치 기반으로 찾을 수 있음
- 원하는 지역이나 건물 등 검색 가능

- 여러 게시글을 조회할 수 있음
- 이때 일정 수치의 사실 버튼을 누르면 해당 지역의 사람들에게 알림이 전송됨
- 알람을 보낼 때 gpt를 활용하여 재난의 위험성을 판단함
시연 영상
홈 화면

게시물 등록
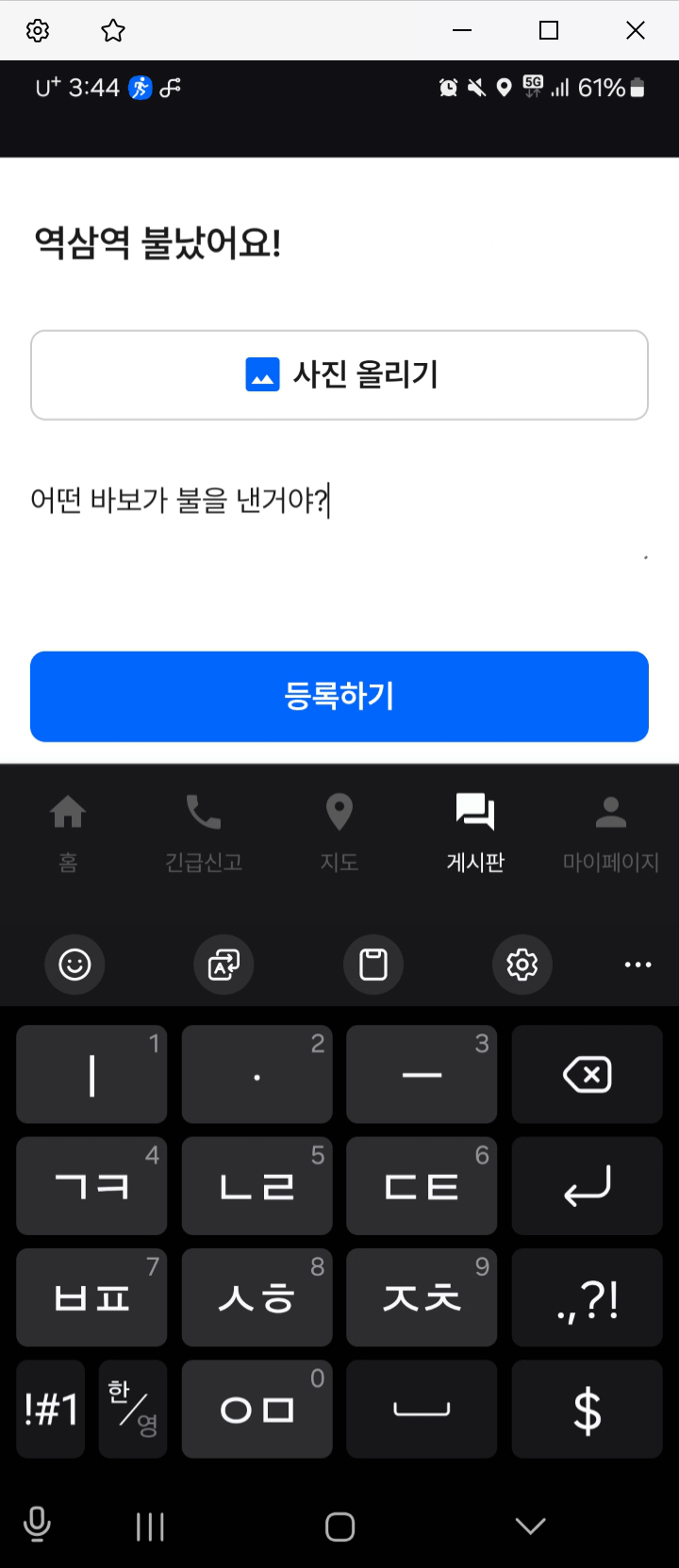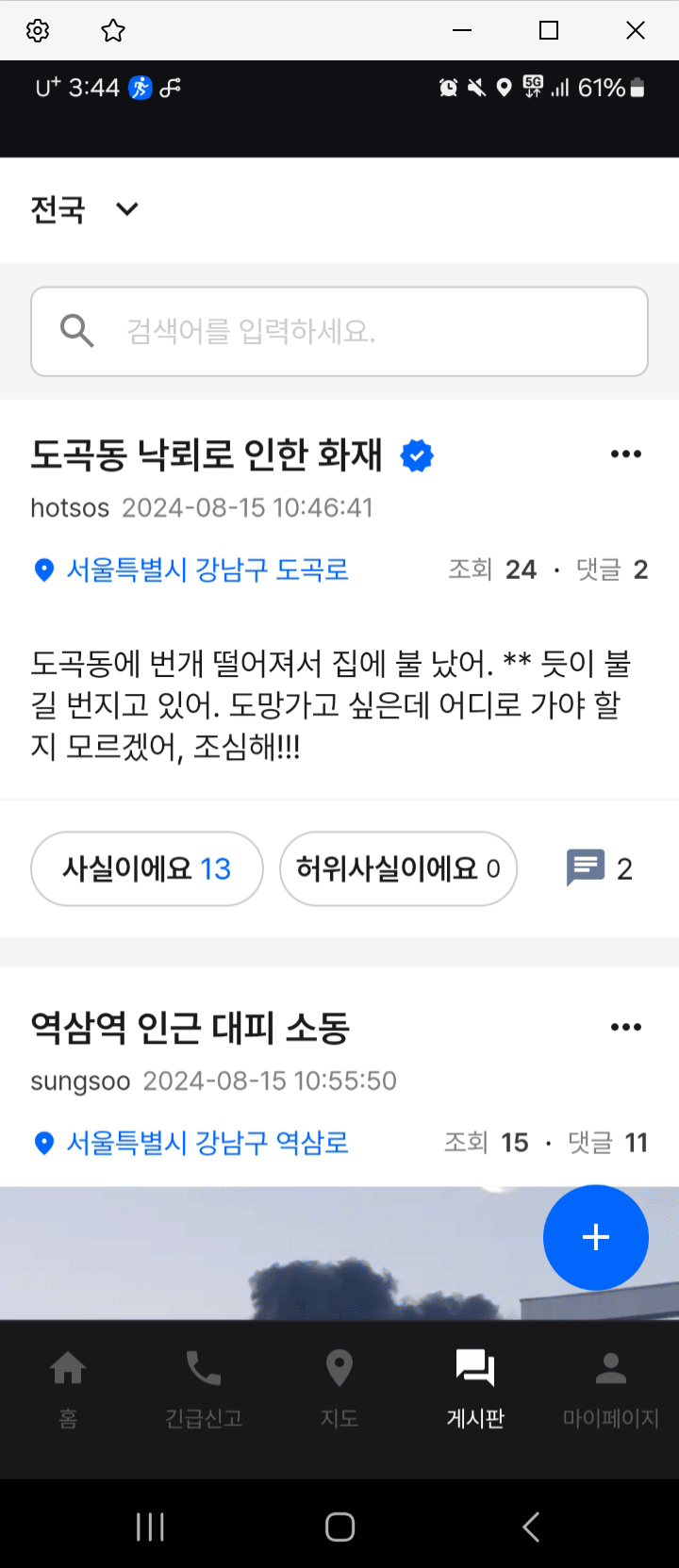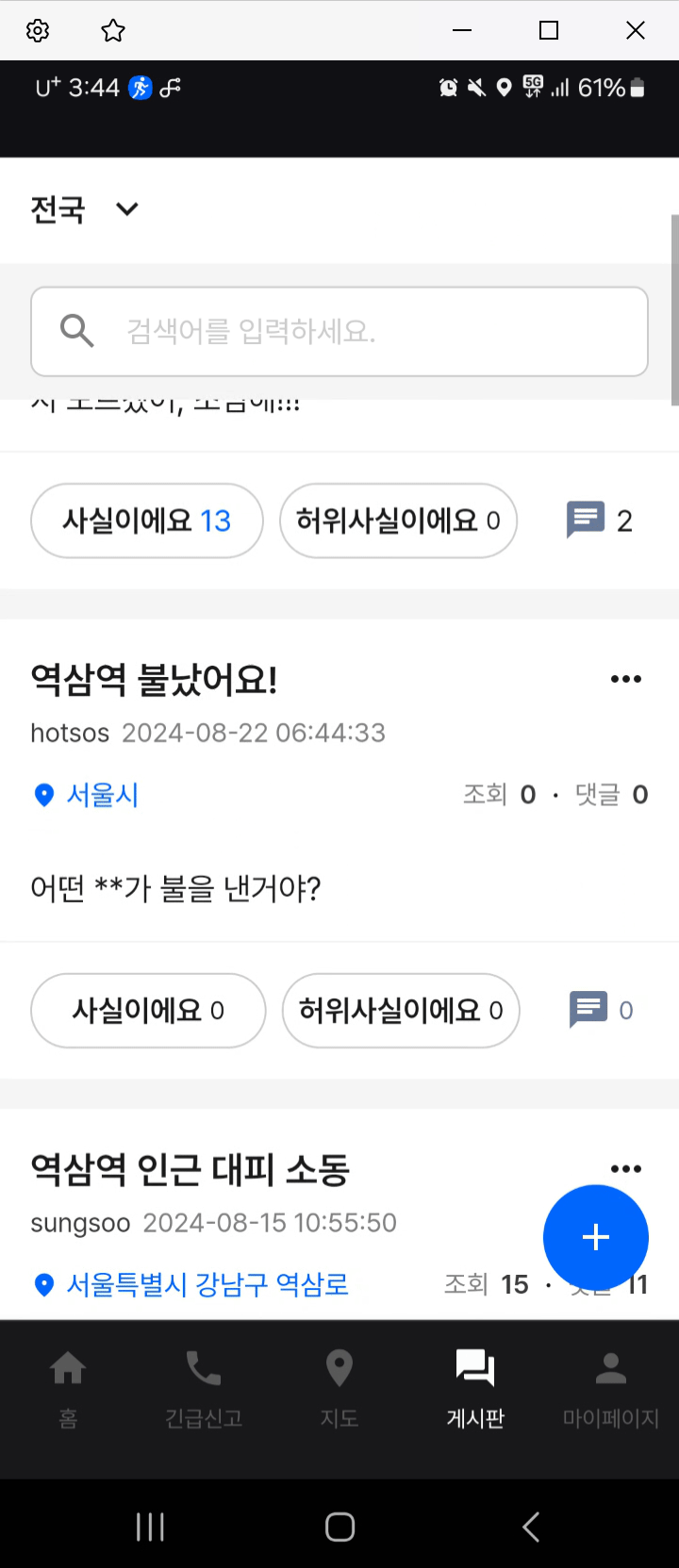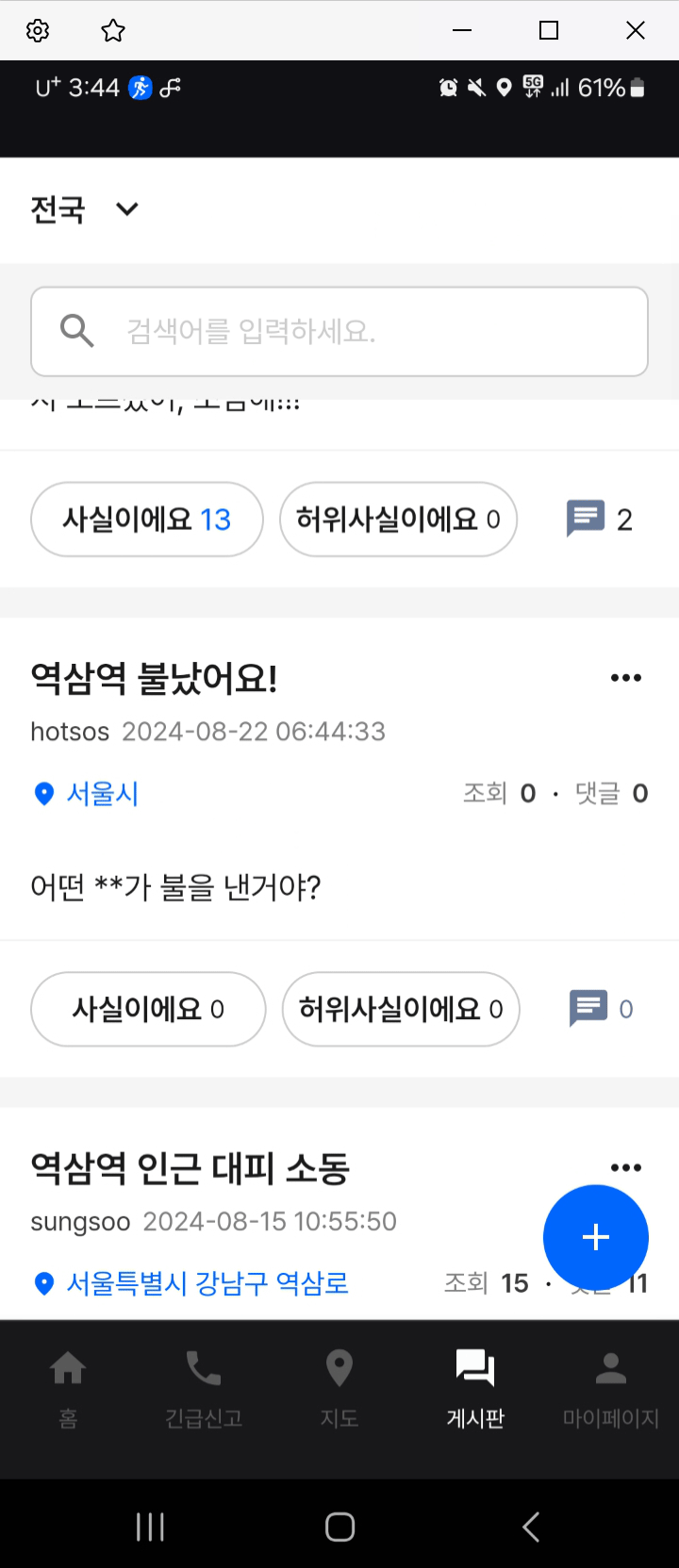
욕설 필터링 기능 적용
재난문자 알림

재난 문자 상세

재난 문자 필터

핫 게시물 등록

지도

마무리
이번 프로젝트를 하면서 많은 것을 배웠고 재미있었다.
팀원들이 다들 열심히 해서 좋은 결과물을 얻었고 뿌듯한 것 같다.
2주 넘게 야근을 한 것 같다..
프로젝트 동안 새로운 기술을 적용해보기도 하고 새로운 지식도 얻어서 더 의미가 있었다.
현재도 다른 프로젝트를 진행 중인데 꾸준히 열심히 하자.
이번에는 재난 알리미라는 어플을 만들었다.
평소에 바쁜 일상 때문인지 나의 나태함 때문인지 글을 오랜만에 작성하게 되었다.
프로젝트 전체적인 정리, 핵심기능을 작성하려 한다.
재난 알리미가 무엇인가?
- 위와 같이 현재 존재하는 재난 알림은 나의 위치기반으로 한 재난 알림만 받을 수 있기에 지인의 정보도 얻을 수 있도록 하고 싶었다.
- AED나 대피소와 같은 위치 기반 조회 시스템이 부족하다고 생각했다.
- 인위재난의 경우 빠르게 알아채기 어렵다.
이러한 니즈를 해소하기 위해 개발을 시작했다.
서비스의 특징
Spring Security
스프링 시큐리티를 활용하여 로그인을 구현하였다.
Security Config
@Configuration
@EnableWebSecurity
@RequiredArgsConstructor
public class SecurityConfig {
private final JwtAuthenticationFilter jwtAuthenticationFilter;
private final ExceptionHandlerFilter exceptionHandlerFilter;
// CORS 설정
CorsConfigurationSource corsConfigurationSource() {
return request -> {
CorsConfiguration config = new CorsConfiguration();
config.setAllowedHeaders(Collections.singletonList("*"));
config.setAllowedMethods(Collections.singletonList("*"));
config.setAllowedOriginPatterns(Arrays.asList("http://localhost:3000", "https://i11a607.p.ssafy.io", "http://10.0.2.2:3000","https://mono-repo-practice.vercel.app/"));
config.setAllowCredentials(true);
return config;
};
}
// Password 인코딩 방식에 BCrypt 암호화 방식 사용
@Bean
public PasswordEncoder passwordEncoder() {
return new BCryptPasswordEncoder();
}
@Bean
public WebSecurityCustomizer webSecurityCustomizer() { // security를 적용하지 않을 리소스
return web -> web.ignoring()
// error endpoint를 열어줘야 함, favicon.ico 추가!
.requestMatchers("/error", "/favicon.ico","/swagger-ui/**","/swagger-resources/**","/v3/api-docs/**",
"/swagger-ui.html/**");
}
@Bean
public SecurityFilterChain filterChain(HttpSecurity http) throws Exception {
http
// CSRF 보호 기능 비활성화, 세션을 사용하지 않기때문에
.csrf((csrfConfig) ->
csrfConfig.disable()
)
// Clickjacking 공격을 방지하기 위한 X-Frame-Options 헤더 비활성화
// 캐시 제어 비활성화
.headers((headerConfig) ->
headerConfig.frameOptions(frameOptionsConfig ->
frameOptionsConfig.disable()
)
.cacheControl(cacheControl -> cacheControl.disable())
)
// session 사용 X 명시
.sessionManagement((sessionConfig) ->
sessionConfig.sessionCreationPolicy(SessionCreationPolicy.STATELESS)
)
.cors(corsConfigurer -> corsConfigurer.configurationSource(corsConfigurationSource()))
// HTTP 요청에 대한 보안 설정
.authorizeHttpRequests(authorizeRequests ->
authorizeRequests
// '/login', '/oauth2' 나머지 모든 요청은 인증된 사용자만 접근 가능
.requestMatchers("/register", "/login", "/register/duplicate","/reissue","/login/oauth", "/oauth2/**"
,"/login/oauth2/**", "/error", "login/oauth2/code/kakao","/swagger-ui/**"
,"/swagger-resources/**", "/v3/api-docs/**", "/fcm/test", "/sms/**", "/locations/**").permitAll()
// .requestMatchers("/**").permitAll()
// .requestMatchers("/admin").hasRole("ADMIN") // admin은 ADMIN 롤만
.anyRequest().authenticated()
)
.addFilterBefore(jwtAuthenticationFilter, UsernamePasswordAuthenticationFilter.class)
.addFilterBefore(exceptionHandlerFilter, JwtAuthenticationFilter.class);
return http.build();
}
}
Jwt
JwtAuthenticationFilter
/**
* OncePerRequestFilter : 요청당 한 번만 실행되어야 하는 작업 시 사용
* 모든 요청에 대해서 JWT를 검증함
*/
@Slf4j
@Component
@RequiredArgsConstructor
public class JwtAuthenticationFilter extends OncePerRequestFilter {
private final JwtTokenProvider jwtTokenProvider;
private final AntPathMatcher antPathMatcher = new AntPathMatcher();
private static final List<String> EXCLUDE_URLS = Arrays.asList(
"/register", "/login", "/reissue", "/login/oauth", "/oauth2/**", "/login/oauth2/**", "/error",
"/login/oauth2/code/kakao", "/swagger-ui/**", "/swagger-resources/**", "/v3/api-docs/**", "/fcm/test",
"/register/duplicate", "/sms/**", "/locations/**"
);
@Override
protected void doFilterInternal(HttpServletRequest request, HttpServletResponse response, FilterChain filterChain) throws ServletException, IOException {
String requestURI = request.getRequestURI();
// 제외할 URI들
if (isExcluded(requestURI)) {
filterChain.doFilter(request, response);
return;
}
// 유효한 토큰인지 확인
String token = jwtTokenProvider.resolveToken(request);
if(token == null) {
filterChain.doFilter(request, response);
return;
}
if(!jwtTokenProvider.validateToken(token))
throw new CustomJwtException(ErrorCode.EXPIRED_JWT_TOKEN, "Access token이 만료됐습니다.");
// 토큰에서 userId와 role 추출
Claims payload = jwtTokenProvider.getPayload(token);
int userId = jwtTokenProvider.getUserIdFromPayload(payload);
Role role = jwtTokenProvider.getRoleFromPayload(payload);
// SecurityContextHolder에 토큰에서 추출한 userId와 role을 바탕으로 만든 authentication 넣기
UserDetails userDetails = new PrincipalDetails(userId, role);
UsernamePasswordAuthenticationToken authentication = new UsernamePasswordAuthenticationToken(userDetails, null, userDetails.getAuthorities());
authentication.setDetails(new WebAuthenticationDetailsSource().buildDetails(request));
SecurityContextHolder.getContext().setAuthentication(authentication);
filterChain.doFilter(request, response);
}
private boolean isExcluded(String requestURI) {
return EXCLUDE_URLS.stream().anyMatch(url -> antPathMatcher.match(url, requestURI));
}
}
JwtTokenProvider
/**
* Jwt Token util
*/
@Slf4j
@Component
public class JwtTokenProvider {
// todo: application.yml 변경공유 (secret key, expiration time)
private final SecretKey secretKey;
private final String userInfoSecretKey;
private final long accessTokenExpireTime;
private final long refreshTokenExpireTime;
public static final String TOKEN_PREFIX = "Bearer ";
public static final String HEADER_STRING = "Authorization";
private final AES256SecureUtil aes256SecureUtil;
private final Set<String> invalidatedTokens = new HashSet<>();
// todo: static 변수를 생성자를 통해 할당이 맞는지
public JwtTokenProvider(@Value("${spring.jwt.secret}") String secretKey,
@Value("${spring.jwt.user-info-secret}") String userInfoSecretKey,
@Value("${spring.jwt.access_expiration_time}") long accessTokenExpireTime,
@Value("${spring.jwt.refresh_expiration_time}")long refreshTokenExpireTime){
this.userInfoSecretKey = userInfoSecretKey;
this.secretKey = Keys.hmacShaKeyFor(Decoders.BASE64URL.decode(secretKey)); // secretKey도 일반 문자열이 아닌 암호화된 문자열로
this.aes256SecureUtil = new AES256SecureUtil(userInfoSecretKey);
this.accessTokenExpireTime = accessTokenExpireTime;
this.refreshTokenExpireTime = refreshTokenExpireTime;
}
/**
* accessToken의 내용으로 새로운 accessToken을 만듭니다.
* @param accessToken
* @return
*/
public String reissue(String accessToken) {
Claims payload = getPayload(accessToken);
Integer userId = getUserIdFromPayload(payload);
Role role = getRoleFromPayload(payload);
return createAccessToken(userId, role);
}
// token 발급
public JwtToken issue(int userId, Role role) {
return new JwtToken(createAccessToken(userId, role), createRefreshToken());
}
//access token 생성
public String createAccessToken(int userId, Role role){
//userId와 role은 민감한 정보이기 때문에 암호화해서 payload에 넣어야 한다.
Date expireationDate = new Date(System.currentTimeMillis() + accessTokenExpireTime);
String userIdEncrypt = aes256SecureUtil.encrypt(Integer.toString(userId), expireationDate.toString());
String userRoleEncrypt = aes256SecureUtil.encrypt(role.toString(), expireationDate.toString());
Claims claims = Jwts.claims()
.subject("UserInfo")
.add("userId", userIdEncrypt)
.add("role", userRoleEncrypt)
.issuedAt(new Date())
.expiration(new Date(System.currentTimeMillis() + accessTokenExpireTime)).build();
return Jwts.builder()
.header()
.keyId("KeyId")
.and()
.claims(claims)
.signWith(secretKey, Jwts.SIG.HS256)
.compact();
}
//refresh token 생성
public String createRefreshToken(){
Claims claims = Jwts.claims()
.issuedAt(new Date())
.expiration(new Date(System.currentTimeMillis() + refreshTokenExpireTime)).build();
return Jwts.builder()
.header()
.keyId("KeyId")
.and()
.claims(claims)
.signWith(secretKey, Jwts.SIG.HS256)
.compact();
}
// payload 추출
public Claims getPayload(final String token) {
try {
return Jwts.parser()
.verifyWith(secretKey)
.build()
.parseSignedClaims(token)
.getPayload();
} catch (ExpiredJwtException e) {
return e.getClaims();
}
}
// userId 추출. 복호화 해야 한다.
public int getUserIdFromPayload(final Claims claims) {
String userId = claims.get("userId", String.class);
return Integer.parseInt(aes256SecureUtil.decrypt(userId, claims.getExpiration().toString()));
}
// role 추출. 복호화 해야 한다.
public Role getRoleFromPayload(Claims claims) {
String userRole = claims.get("role", String.class);
return Role.valueOf(aes256SecureUtil.decrypt(userRole, claims.getExpiration().toString()));
}
/**
* JWT 토큰의 유효성을 검증
* @param token JWT 토큰
* @return 토큰이 유효하면 true, 그렇지 않으면 false
*/
public boolean validateToken(final String token) {
try {
//jwt가 위변조되지 않았는지 secretKey를 이용해 확인
Jws<Claims> claims = Jwts.parser()
.verifyWith(secretKey)
.build()
.parseSignedClaims(token);
return true;
} catch(SecurityException | MalformedJwtException e){
throw new CustomJwtException(ErrorCode.INVALID_JWT_TOKEN);
} catch (ExpiredJwtException e) {
//refreshToken의 만료 상황과 accessToken의 만료 상황을 구분하기 위해
//호출 클래스에서 예외 처리
return false;
} catch (UnsupportedJwtException e){
throw new CustomJwtException(ErrorCode.UNSUPPORTED_JWT_TOKEN);
} catch (IllegalArgumentException e){
e.printStackTrace();
throw new CustomJwtException(ErrorCode.ILLEGAL_JWT_TOKEN);
}
}
/**
* 요청 헤더에서 JWT 토큰 추출
* @param request HTTP 요청
* @return JWT 토큰
*/
public String resolveToken(HttpServletRequest request) {
String bearerToken = request.getHeader(HEADER_STRING)
if (bearerToken != null && bearerToken.startsWith(TOKEN_PREFIX)) {
return bearerToken.substring(7);
}
return null;
}
public String resolveToken(String bearerToken) {
if (bearerToken != null && bearerToken.startsWith(TOKEN_PREFIX)) {
return bearerToken.substring(7);
}
return null;
}
}
들었던 의문점
- SecurityContextHolder의 역할 (세션 없이 동작하는 경우)
Spring Security에서 SecurityContextHolder는 현재 실행 중인 스레드의 SecurityContext를 저장하는 역할을 한다. 이 SecurityContext는 현재 사용자의 인증 정보 (Authentication)를 포함하고 있다. 일반적으로는 이 SecurityContext가 세션과 연동되지만, 세션을 사용하지 않는 경우에도 SecurityContextHolder는 여전히 중요한 역할을 한다.
- 왜 필요한가?: SecurityContextHolder는 현재 요청을 처리하는 동안 인증된 사용자의 정보를 저장하고, 다른 보안 관련 로직에서 이 정보를 참조할 수 있도록 한다. 예를 들어, @PreAuthorize 같은 어노테이션을 사용하거나, 서비스 레이어에서 인증된 사용자의 정보를 가져올 때 SecurityContextHolder를 활용함.
- 세션 없이 어떻게 작동하는가?: 세션을 사용하지 않으면, SecurityContextHolder는 요청별로 SecurityContext를 관리한다. 즉, 요청이 들어올 때 JWT 토큰을 검증하고, SecurityContext에 인증 정보를 설정한 다음, 해당 요청이 끝나면 SecurityContext가 비워지거나 삭제된다. 따라서 세션을 사용하지 않더라도 매 요청마다 인증을 처리할 수 있다.
- SecurityContextHolder.getContext(). setAuthentication(authentication)에 대한 동작 방식
JwtAuthenticationFilter에서 SecurityContextHolder.getContext(). setAuthentication(authentication);를 호출하는 이유는, 현재 요청에 대한 인증 정보를 SecurityContext에 저장하기 위해서이다. 이 작업은 매 요청마다 반복되지만, 각 요청이 별도의 스레드에서 실행되므로 SecurityContextHolder에 저장된 인증 정보는 해당 요청이 끝날 때까지 해당 스레드에만 영향을 미친다.
- 매 요청마다 context가 쌓이는 작업인가?: 아니다. SecurityContext는 각 요청마다 새로 생성된다. 따라서 매 요청마다 인증 정보가 SecurityContext에 설정되고, 요청이 끝나면 SecurityContext가 비워지거나 폐기된다. 이는 세션을 사용하지 않는 경우에도 동일하게 작동함.
- JWT와 Refresh Token의 유효기간이 같게되면 Refresh Token은 의미가 있을까?
Ref와 JWT의 만료시간이 동일하다고 쳤을 때, Ref 와 JWT 가 동시에 생성되어서 동시에 만료된다 한들, 이 둘이 항상 동일하게 사용되는 게 아니다.
예를 들어 금융권에서 Ref 30분 JWT 30분 이렇게 만들어졌다고 가정하고 JWT의30분 중 약 25분 정도 소진되어 JWT의 만료가 가까워졌을 때, 남은 5분 사이에 서비스를 더 사용할지 이대로 종료시킬지 사용자가 반드시 확인하는 순간을 만들고, 이때 JWT 갱신을 택하게 되면, 남은 5분 내에 JWT를 갱신하기 위한 키로써 Ref의 유효 시간을 갖는다.
- Login 이후 JWT/Ref를 받은후, 다음 매 Req 마다 JWT와 Ref를 보내서 Ref로 만료일 파악하고 JWT로 인증처리하는 방식에 대한 고찰
동접자 1000만을 생각해 보면REST 1천만으로 서비스가 가능한기? - 대충 2천만이라 가정
전통적인 방식 기준으로 1 API는1 Req에 1 DB Conn 하던가? - 대충 4 DB 한다 치자.
그럼 Conn Pool 이 1천만 * 2 * 4
Req 2천만 + DB 8천만의 Conn 값이 있다. - 1억 Conn이다.
여기서 BE의BE의 1DB, 25% (2천만 정도 Conn)이라도 줄이려는 목적이다.
- JWT는 DB conn을 줄이려고 태어난 거다.
Ref로 매번 DB를 갔다 오는 것은 동작은 되지만, 그럼 또 DB Conn 이 1 늘어나는 문제는 해결되지 않는다.
AccessToken과 달라진 게 없이 굳이 JWT를 써야 하는가?
Server에서만Ref 만료일 확인하고, JWT로 인증하면 되는 것이다.
DB 다녀올 것 없이, 처음부터 JWT에 만료일 넣고, DB는 Ref를 갱신할 때만 접속하면 된다.
크롤링
실시간 재난 문자 발생 여부를 파악하기 위해 1분마다 재난문자를 국민재난안전포털을 통해 크롤링해 저장하고 있다.
현재 1분 주기로 크롤링을 진행하지만 추후 대규모 API 시스템과 연동이 된다면 즉시 발송가능할 수 있도록 설계하였다.
자동화된 프로그램을 사용해 웹사이트의 데이터를 수집하는 과정-> Selenium WebDriver를 사용
// 위 그림과 같이 내가 크롤링 하고 싶은 부분을 copy하면 되는데
// 개발자모드 -> 마우스포인터 -> copy -> XPath하고나서 아래와 같은 형식으로
// 붙여넣으면 됨
WebElement messageElement = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MSG_CN']"));
String message = messageElement.getText();
WebElement messageElement2 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MD101_SN']"));
String disasterNo = messageElement2.getText();
WebElement messageElement3 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_DSSTR_SE_NM']"));
String classification = messageElement3.getText();
Crawler
@Slf4j
@Component
public class Crawler {
public static final String WEB_SITE_ADDRESS = "https://www.safekorea.go.kr/idsiSFK/neo/sfk/cs/sfc/dis/disasterMsgList.jsp?menuSeq=679";
private static final int FETCH_WAIT_SECONDS = 10;
private static final int SCHEDULE_DELAY_MS = 60000;
private static int lastNo;
private final DisasterService disasterService;
public Crawler(final DisasterRepository disasterRepository, final DisasterService disasterService) {
Integer maxSerialNumber = disasterRepository.findMaxSerialNumber();
lastNo = maxSerialNumber != null ? maxSerialNumber : 1;
this.disasterService = disasterService;
}
@Scheduled(fixedDelay = SCHEDULE_DELAY_MS)
public void checkUpdateNews() {
WebDriverManager.chromedriver().setup();
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--no-sandbox");
options.addArguments("--disable-dev-shm-usage");
WebDriver driver = new ChromeDriver(options);
String baseUrl = WEB_SITE_ADDRESS;
driver.get(baseUrl);
try {
// 맨 위의 번호 요소를 찾습니다.
WebElement messageElement = driver.findElement(By.xpath("//*[@id='disasterSms_tr_0_MD101_SN']"));
int disasterNo = Integer.parseInt(messageElement.getText());
// 제일 최신값 비교해서 다르면 크롤링 시작, 같으면 작업 x
if (disasterNo != lastNo) {
List<CrawInfo> crawInfos = performCrawling(disasterNo - lastNo);
lastNo = disasterNo;
makeDisaster(crawInfos);
}
} catch (Exception e) {
System.out.println("An error occurred while fetching the disaster number: " + e.getMessage());
} finally {
driver.quit();
}
}
public void makeDisaster(List<CrawInfo> crawInfos) throws ParseException, IOException {
List<CrawInfo> result = new ArrayList<>();
// 아래 작업은 지역이름이 여러개인지 체크
for (CrawInfo crawInfo : crawInfos) {
String[] locationInfo = crawInfo.getLocation().split(", ");
if (locationInfo.length == 1) { // 정상인 경우 ex) 전북특별자치도 진안군
result.add(crawInfo);
} else { // 여러개인 경우 ex) 전북특별자치도 진안군, 전북특별자치도 장수군
String[] now = Arrays.stream(locationInfo)
.map(location -> {
String[] info = location.split(" ");
return info[0] + " " + info[1];
})
.distinct()
.toArray(String[]::new); // 여러개인데 중복일 경우 ex) 경기도 수원시 장안구, 경기도 수원시 권선구 -> 경기도 수원시
// 각각의 지역으로 추가
for (String info : now) {
result.add(CrawInfo.of(crawInfo, info));
}
}
}
disasterService.saveAll(result);
}
public List<CrawInfo> performCrawling(final int count) {
WebDriverManager.chromedriver().setup();
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--no-sandbox");
options.addArguments("--disable-dev-shm-usage");
options.addArguments("--disable-gpu");
options.addArguments("--ignore-ssl-errors=yes");
options.addArguments("--ignore-certificate-errors");
WebDriver driver = new ChromeDriver(options);
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(FETCH_WAIT_SECONDS));
String baseUrl = WEB_SITE_ADDRESS;
driver.get(baseUrl);
List<CrawInfo> crawInfos = new ArrayList<>();
int i = 0;
while (i < count) {
try {
WebElement messageElement = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MSG_CN']"));
String message = messageElement.getText();
WebElement messageElement2 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_MD101_SN']"));
String disasterNo = messageElement2.getText();
WebElement messageElement3 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_DSSTR_SE_NM']"));
String classification = messageElement3.getText();
// log.info("재난문자 발생!!! {}", classification);
// if(classification.equals("기타")) continue;
WebElement messageElement4 = driver.findElement(By.xpath("//*[@id='disasterSms_tr_" + i + "_EMRGNCY_STEP_NM']"));
String level = messageElement4.getText();
messageElement.click(); // 세부 정보를 보기 위해 클릭
// 세부 정보에서 메시지 내용 가져오기
wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//*[@id='msg_cn']")));
WebElement detailMessageElement = driver.findElement(By.xpath("//*[@id='msg_cn']"));
String detailMessage = detailMessageElement.getText();
WebElement locationElement = driver.findElement(By.xpath(" //*[@id=\"bbsDetail_0_cdate\"]"));
String location = locationElement.getText();
crawInfos.add(new CrawInfo(message, disasterNo, classification, level, detailMessage, location));
driver.navigate().back(); // 다시 목록으로 돌아가기
wait.until(ExpectedConditions.visibilityOfElementLocated(By.xpath("//*[@id='disasterSms_tr_" + (i + 1) + "_MSG_CN']")));
i++;
} catch (Exception e) {
// 더 이상 요소가 없을 때 예외가 발생하면 루프를 종료합니다.
break;
}
}
driver.quit();
return crawInfos;
}
}크롤링 사이트의 경우 번호 자체가 존재하여 새로운 글이 올라왔는지 확인이 가능하다.
이때 서버를 처음 킬 때 DB에 가장 큰 번호를 static변수로 가져와서 이후부터 업데이트 됐는지 판단할 때는 디비를 거칠 필요가 없어졌다.
GPT
우리 서비스의 경우 재난 문자가 오지 않는 상황이라 하더라도 게시판을 통해 실시간으로 긴급 상황을 파악할 수 있다.
하지만 욕설이나 개인정보와 같이 필터링이 필요한 정보까지 언급될 경우를 대비하고자 생성형 AI를 활용해 이를 적절히 처리하는 방법을 구현하였다.
또한 핫이슈 게시물이 등록될 경우 게시물 내용을 알람으로 보내는 것이 아니라, 게시물 내용을 AI를 활용해 사고 유형 및 심각성을 파악하도록 하고 어떤 상황에 대한 게시물인지에 대해 일관된 형식으로 알람을 보내도록 했다.
프롬프트 개선
처음에는 단순히 GPT에게 어떠한 작업을 해달라고 작성만 했었다.
하지만 이를 개선하기 위해 아래와 같은 방식을 사용했다.
- gpt에게 role(역할)을 부여해서 이전보다 정확도를 높임
- gpt api를 사용하면서 용도에 따라 System, User, Assistant를 구분해서 아래와 같은 형식으로 진행함
- System - ChatGPT에게 어떻게 행동을 할지 지정하는 기능
- Assistant 근데 System에 다 풀어서 적어도 어느 정도 잘되더라 - 이전 대화를 저장하고 연속성을 유지하기 위해 사용
- User - 우리가 하는 질문(prompt) 내용
FCM
실시간 push 알림을 위해서 FCM(Firebase Cloud Messaging)을 선택함
알림을 구현하는 방식에는 Socket과 SSE 등이 있는데
FCM을 쓴 이유는 실시간성, 서버 안정성 측면에서 채택함
실시간성
우리 메인 서버가 알림을 보내는 로직을 수행 중인데 다른 작업 먼저 수행하는 상황이 발생하면 실시간성 알림이 보장되지 않음
실시간성을 보장하기 위해서는 지속적으로 연결상태를 유지해야 함
SSE, 소켓으로 구현하였을 때 얼마나 실시간성이 보장되고 지속적인 연결상태가 유지될지에 대한 의문점
복잡성
푸시 알림을 보낼 때에는 웹, 모바일 등의 플랫폼에 따라 다르게 보내줘야 함
⇒ 알림 기능의 실시간성을 보장하고 플랫폼에 종속되지 않기 위해 FCM을 사용함
FCM 동작원리
💡 FCM은 웹, 모바일 상황에서 device를 등록하고 추적해서 알림을 보내는 것이 아니다.
firebase 서버에서 발급된 fcmtoken을 고유키로 설정되면 푸시 알림은 fcmtoken을 기반으로 알림을 보내는 것이다.
- Firebase 서버에서 fcm을 보내기 위한 fcmtoken 발급 요청을 한다.
- Firebase 서버에서 fcmtoken을 발급받는다.
- Fcm 알림을 요청하면 발급된 fcmtoken을 목적지로 push 알림을 보낸다.
Firestore
위에서 FCM 동작수행을 위해서는 FCM토큰을 어딘가에 저장해야 한다.
이것을 어디에 저장할까 고민하다가 메인 DB인 mysql에 저장하면 되겠다는 생각을 했다.
하지만 fcm 알림을 보낼 때 서버와 DB 간의 통신을 최소화하고자 했고, firestore에 저장하는 것을 결정했다.
💡 Firestore VS Realtime DB 파이어베이스에는 db가 크게 두 가지 있음 우리 프로젝트에서는 복잡한 쿼리가 필요한 상황이라서 firestore를 사용하는 게 맞음 RealtimeDB는 단순쿼리와 필드구성이 복잡하지 않은 상황에서 사용하는 것이 적합함
Functions
💡Firebase용 Cloud Functions는 Firebase 기능과 HTTPS 요청에 의해 트리거 되는 이벤트에 응답하여 백엔드 코드를 자동으로 실행할 수 있는 서버리스 프레임워크입니다. 이 말을 쉽게 말하면 내가 firebase 기능을 사용할 로직을 메서드로 정의하고, firebase 서버에 배포하면, 배포된 url을 불러서 필요할 때 사용가능
functions를 사용하는 이유
functions를 사용하는 이유는 분리된 서버에서 파이어베이스 기능을 사용하기 위함이다.
분리된 서버에서 firebase기능을 사용하면 좋은 점은 우리 서버의 부하를 줄이고, 안정성 있게 fcm기능을 활용가능함
functions 기능으로 할 수 있는 것
예시를 들어서 설명하면 요청 시 body에 담아서 넘어온 userId, fcmToken, sido, gugun을 users 컬렉션에 token, sido, gugun, favoriteSido, favoriteGugun필드에 담는 로직임
exports.join = functions.https.onRequest(async (req, res) => {
const { userId, fcmToken, sido, gugun } = req.body;
if (!userId || !fcmToken || !sido || !gugun) {
console.error('Invalid request parameters:', { userId, fcmToken, sido, gugun });
return res.status(400).send('userId, fcmToken, sido, and gugun are required.');
}
try {
await admin.firestore()
.collection('users')
.doc(userId)
.set({
token: fcmToken,
sido: sido,
gugun: gugun,
favoriteSido: "",
favoriteGugun: "",
});
console.log('User data saved to Firestore:', { userId, sido, gugun });
return res.status(200).send('User data saved successfully');
} catch (error) {
console.error('Error saving user data to Firestore:', error);
return res.status(500).send('Error saving user data');
}
});이제 이렇게 만든 함수를 아래 명령어를 통해
firebase deploy --only functions
클라우드서버에 배포된 것을 확인하고 이제 내가 파이어베이스 db에 저장할 때 join url로 body만 잘 담아서 보내주면 됨
exports.sendBoardOwner = functions.https.onRequest(async (req, res) => {
const data = req.body;
const { alarmType, keyword, textList, title, content, userId, keyId, alarmId } = data;
// 필수 파라미터 확인
if (!userId || !title || !content) {
console.error('Invalid request parameters:', { userId, title, content });
return res.status(400).send('userId, title, and content are required.');
}
try {
console.log(`Received request to send notification to userId: ${userId}`);
// Firestore에서 userId가 일치하는 사용자 조회
const userRef = admin.firestore().collection('users').doc(userId);
const userDoc = await userRef.get();
if (!userDoc.exists) {
console.log(`No matching user found for userId: ${userId}`);
return res.status(404).send('No matching user found.');
}
const userData = userDoc.data();
if (!userData.token) {
console.log(`No FCM token found for userId: ${userId}`);
return res.status(404).send('No FCM token found for the specified user.');
}
// 알람 데이터를 사용자 문서의 alarms 하위 컬렉션에 저장
const alarmData = {
alarmType: alarmType || 'default', // 기본값 설정
keyword: keyword || '',
textList: textList || [],
title: title,
content: content,
timestamp: admin.firestore.FieldValue.serverTimestamp(),
keyId : keyId,
alarmId : alarmId,
isRead : 'N',
notificationType : 'personal'
};
try {
const userAlarmsRef = userRef.collection('alarms').doc();
await userAlarmsRef.set(alarmData);
console.log(`Alarm data saved for userId: ${userId}`);
} catch (error) {
console.error('Error saving alarm data:', error);
return res.status(500).send('Error saving alarm data: ' + error.message);
}
// 알람 데이터가 성공적으로 저장된 후 FCM 알림 전송
const token = userData.token;
const payload = {
notification: {
title: title,
body: content,
},
token: token,
};
const response = await admin.messaging().send(payload);
console.log('Successfully sent message:', response);
return res.status(200).send('Notification sent and alarm data saved successfully');
} catch (error) {
console.error('Error sending message:', error);
return res.status(500).send('Error sending message: ' + error.message);
}
});지금 이예시가 functions를 쓰는 이유임.
우선 sendBoardOwner 메서드는 댓글을 달 때마다 게시판 주인에게 알림을 보내기 위해 만든 메서드다.
크게 설명하면 users 컬렉션에서 게시판 작성자 알림 데이터를 저장하고, 게시판주인에게 알림을 보내라는 로직이다.
Token
알림 키워드 토큰화
재난문자는 국가에서 제공되므로 이를 그대로 전달하면 중복 상황이 발생할 수 있다.
또한, 모든 알람을 데이터베이스에 중복 저장하는 것은 비효율적이다.
이를 해결하기 위해 저희는 재난 키워드를 추출해 템플릿 화하고, 일관된 형식으로 가독성을 높였다.
또한, 미리 카테고리화된 키워드를 사용해 불필요한 정보 저장을 줄였다.
구현 방법
- 키워드를 Enum으로 관리 (열대야, 소나기, 물놀이, 산사태 …)
- 토큰 추출 메서드 정의 (firebase에 저장되는 토큰)
- 토큰으로 알람 내용 만드는 메서드 정의 (사용자에게 보내지는 알람 내용)
- 키워드가 NONE이면 파이어베이스에 알람 내용 전체가 들어 있다고 가정
- 재난 문자 content에 키워드가 들어있는지 contains로 체크
AlarmKeyword
@Getter
public enum AlarmKeyword {
TROPICAL_NIGHT("열대야",
content -> List.of(),
tokens -> "오늘밤 열대야가 예상되오니, 적정실내온도설정, 미지근한 물 샤워, 가벼운 운동으로 건강관리에 유의하시기 바랍니다."),
SHOWER("소나기",
content -> {
// mm이 포함된 숫자나 범위를 추출하기 위한 정규 표현식
Pattern pattern = Pattern.compile("(약\\s*)?\\d+~?\\d*mm");
Matcher matcher = pattern.matcher(content);
String rainfallAmount = "";
while (matcher.find()) {
rainfallAmount = matcher.group();
}
return List.of(rainfallAmount);
},
tokens -> {
if (tokens.get(0).isEmpty()) {
return "소나기가 내릴 예정입니다. 산간계곡, 하천변 산책로 등 위험지역 출입을 자제하시기 바랍니다.";
}
return tokens.get(0) + "의 소나기가 내릴 예정입니다. 산간계곡, 하천변 산책로 등 위험지역 출입을 자제하시기 바랍니다.";
}),
HEAT_WAVE("폭염",
content -> List.of(),
tokens -> "매우 더운 날씨 지속 중입니다. 수분을 충분히 섭취하고, 현기증·메스꺼움 증상 시 즉시 휴식하세요."),
HEAVY_RAIN("집중호우",
content -> List.of(),
tokens -> "집중호우로 단시간에 급격한 하천 수위상승이 우려되니 하천변 산책로 등 저지대 침수지역 접근을 자제하여 주시기 바랍니다."),
HEAVY_RAIN_ADVISORY("호우주의보",
content -> {
if(content.contains("해제")){
return List.of("해제", content);
}
Pattern pattern = Pattern.compile("\\b\\d{2}:\\d{2}\\b");
Matcher matcher = pattern.matcher(content);
String time = "";
if (matcher.find()) {
time = matcher.group();
}
return List.of("발령",time);
},
tokens -> {
//해제
if(tokens.get(0).equals("해제")){
return tokens.get(1);
}
if(tokens.get(1).isEmpty()){
return "호우주의보가 발령되었습니다. 하천 주변 산책로, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 하천 범람에 주의하세요.";
}
return tokens.get(1) + "에 호우주의보가 발령되었습니다. 하천 주변 산책로, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 하천 범람에 주의하세요.";
}),
HEAVY_RAIN_WARNING("호우경보",
content -> {
Pattern pattern = Pattern.compile("\\b\\d{2}:\\d{2}\\b");
Matcher matcher = pattern.matcher(content);
String time = "";
if (matcher.find()) {
time = matcher.group();
}
return List.of(time);
},
tokens -> {
if(tokens.get(0).isEmpty()){
return "호우경보. 하천 주변, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 대피 권고를 받으면 즉시 대피하세요";
}
return tokens.get(0) + "에 호우경보. 하천 주변, 계곡, 급경사지, 농수로 등 위험 지역에는 가지 마시고, 대피 권고를 받으면 즉시 대피하세요";
});
private final String keyword; // 열대야, 소나기, 열사병, 폭염 등의 키워드
private final Function<String, List<String>> getTokensOp;
private final Function<List<String>, String> getContentOp;
//빠른 조회를 위한 해시맵
private static final Map<String, AlarmKeyword> keywordMap = Collections.unmodifiableMap(Stream.of(values())
.collect(Collectors.toMap(AlarmKeyword::getKeyword, Function.identity())));
AlarmKeyword(String keyword, Function<String, List<String>> getTokensOp, Function<List<String>, String> getContentOp) {
this.keyword = keyword;
this.getTokensOp = getTokensOp;
this.getContentOp = getContentOp;
}
public List<String> getTokens(String content) {
return getTokensOp.apply(content);
}
public String getContent(List<String> tokens) {
return getContentOp.apply(tokens);
}
public static AlarmKeyword getKeyword(String keyword) {
return keywordMap.get(keyword);
}
public static AlarmKeyword getKeyword(Disaster disaster) {
String msg = disaster.getMsg();
return Stream.of(values())
.filter(alarmKeyword -> msg.contains(alarmKeyword.getKeyword()))
.findFirst()
.orElse(null); // 메시지에 해당 키워드가 없으면 null 반환
}
}
N + 1
기존에 게시글을 수정하는 로직에서 디비에 여러 번 접근하는 문제가 발생했다.
이유는 @ManyToOne으로 연결된 entity들이 Lazy로딩으로 설정되어 있어서 실제 사용하는 순간에 디비에 접근하게 된다.
기존의 게시판 수정 코드(member, board, sido, gugun을 찾기 위해 디비에 접근 - select 4번)
@Override
public BoardResponse updateBoard(Integer id, BoardUpdateRequest request, Integer memberId) {
Board board = boardRepository.findById(id)
.orElseThrow(() -> new BoardNotFoundException("Board not found"));
if (!board.getMember().getId().equals(memberId)) {
throw new UnauthorizedBoardAccessException("You are not the owner of this board");
}
board.updateBoard(request.getTitle(), request.getContent());
Board updatedBoard = boardRepository.save(board);
return BoardResponse.from(updatedBoard);
}
이걸 해결하고자 Fetch join을 사용함 -> Board를 가져올 때 필요한걸 같이 한 번에 가져옴
@Query("SELECT b FROM Board b " +
"JOIN FETCH b.member m " +
"JOIN FETCH b.sido s " +
"JOIN FETCH b.gugun g " +
"WHERE b.id = :id")
Optional<Board> findByIdWithMemberAndLocation(@Param("id") Integer id);
이후 로그를 보면 디비에 1번만 접근함
Hibernate:
select
b1_0.id,
b1_0.address,
b1_0.commentNum,
b1_0.content,
b1_0.count,
b1_0.createdAt,
b1_0.factCnt,
b1_0.gugun_id,
g1_0.id,
g1_0.name,
g1_0.sido_id,
b1_0.isAlarm,
b1_0.lat,
b1_0.lon,
b1_0.member_id,
m1_0.id,
m1_0.createdAt,
m1_0.existMemberId,
m1_0.isCertifiedPhone,
m1_0.isIntegrated,
m1_0.isOauth,
m1_0.loginId,
m1_0.name,
m1_0.nickname,
m1_0.oauthType,
m1_0.password,
m1_0.phone,
m1_0.role,
m1_0.status,
m1_0.updatedAt,
b1_0.reportCnt,
b1_0.sido_id,
s1_0.id,
s1_0.name,
b1_0.status,
b1_0.title,
b1_0.updatedAt,
b1_0.version
from
board b1_0
join
member m1_0
on m1_0.id=b1_0.member_id
join
sido s1_0
on s1_0.id=b1_0.sido_id
join
gugun g1_0
on g1_0.id=b1_0.gugun_id
where
b1_0.id=?
인덱스
- 인덱스는 데이터베이스에서 데이터를 빠르게 검색할 수 있도록 도와주는 자료 구조로 책의 목차처럼 특정 데이터의 위치를 빠르게 찾을 수 있게 함
- 하지만 단점으로 인덱스를 생성하고 유지하는데 추가적인 저장 공간이 필요하며 우리는 AED, 대피소 등의 데이터가 잘 안 변해서 상관이 없는데 데이터 삽입, 업데이트, 삭제 시 인덱스도 같이 갱신해야 하기 때문에 약간의 오버헤드가 발생할 수 있음
- 일반적으로 위도와 경도를 기준으로 인덱싱을 할 때 복합인덱스, 공간인덱스로 함
복합 인덱스
- 위도, 경도 두 개의 컬럼을 하나로 묶어서 인덱스 처리하는 것을 말함
ALTER TABLE aed ADD INDEX idx_lat_lon (lat, lon);
SHOW INDEX FROM aed;
--이후 위에 코드를 aed뿐만 아니라 civil_shelter, eo_shelter, et_shelter에 테이블명만 바꿔서 똑같이 적용해주면됨
ALTER TABLE civil_shelter ADD INDEX idx_lat_lon (lat, lon);
ALTER TABLE eo_shelter ADD INDEX idx_lat_lon (lat, lon);
ALTER TABLE et_shelter ADD INDEX idx_lat_lon (lat, lon);
인덱스를 적용한 부분이 위도, 경도를 기준으로 함
동시성 제어
대규모 트래픽이 몰리는 어플 특성상 동시성 이슈가 반드시 발생한다고 생각했음.
일단 동시성 제어를 위해 게시판 조회 시 조회수가 증가하는 로직을 단순히 실행해 봄
원격에서 1000번 요청을 보냄
1번 글에 대한 조회수가 204로 됨
이를 비관적 락을 적용함
2번 글에 대한 조회수가 1000으로 알맞게 나옴
이후 낙관적 락도 적용해 봄
비관적 락
- 장점
- Race Condition이 빈번하게 일어난다면 낙관적 락보다 성능이 좋다.
- DB 단의 Lock을 통해서 동시성을 제어하기 때문에 확실하게 데이터 정합성이 보장된다.
- 단점
- DB 단의 Lock을 설정하기 때문에 한 트랜잭션 작업이 정상적으로 끝나지 않으면 다른 트랜잭션 작업들이 대기해야 하므로 성능이 감소할 수 있다.
낙관적 락
- 장점
- DB 단에서 별도의 Lock을 설정하지 않기 때문에 하나의 트랜잭션 작업이 길어질 때 다른 작업이 영향받지 않아서 성능이 좋을 수 있다.
- 단점
- 버전이 맞지 않아서 예외가 발생할 때 재시도 로직을 구현해야 한다.
- 버전이 맞지 않는 일이 여러 번 발생한다면 재시도를 여러 번 거칠 것이기 때문에 성능이 좋지 않다.
서버 테스트
- 스트레스 테스트와 부하 테스트 차이
1. 대규모 부하 테스트 (Load Testing)
- 대규모 부하 테스트의 주목적은 시스템이 예상되는 최대 부하(예: 최대 사용자 수, 트랜잭션 수)에서도 안정적으로 동작하는지를 확인하는 것이다.
- 시스템의 성능, 응답 시간, 처리량 등을 평가하여 시스템이 정상적으로 운영될 수 있는 한계를 파악한다.
방법:
- 예상되는 실제 운영 환경의 부하 조건을 시뮬레이션
- 일정한 부하를 장기간 유지하여 시스템의 안정성을 평가함.
- 예: 특정 웹 애플리케이션이 1,000명의 동시 사용자를 처리할 수 있는지 테스트.
결과:
- 시스템이 최대 부하에서도 정상적으로 작동하는지 확인.
- 성능 병목 지점과 응답 시간, 처리량 등의 성능 지표를 분석.
2. 스트레스 테스트 (Stress Testing)
- 스트레스 테스트의 주목적은 시스템의 한계를 넘어서 극한 상황에서 시스템이 어떻게 반응하는지 평가하는 것.
- 시스템이 얼마나 많은 부하를 견딜 수 있는지, 그리고 실패 시 어떻게 회복하는지를 확인한다.
방법:
- 시스템의 최대 용량을 초과하는 부하를 가하여 시스템이 언제, 어떻게 실패하는지 관찰한다
- 예를 들어, 점진적으로 부하를 증가시켜 시스템의 한계점까지 도달하게 한다.
- 예상치 못한 상황(예: 네트워크 장애, 서버 다운)에서도 시스템의 회복 능력을 테스트한다.
결과:
- 시스템의 최대 용량과 한계를 파악.
- 시스템의 강인성(resilience)과 안정성, 그리고 장애 발생 시 복구 능력을 평가.
비교 요약특징 대규모 부하 테스트 스트레스 테스트
| 목적 | 최대 부하에서의 안정성 평가 | 시스템 한계와 회복 능력 평가 |
| 방법 | 실제 운영 환경의 최대 부하 시뮬레이션 | 한계점을 초과하는 극한 상황 시뮬레이션 |
| 결과 | 성능 병목, 응답 시간, 처리량 분석 | 시스템의 최대 용량, 실패 지점, 회복 능력 분석 |
| 부하 수준 | 예상 최대 부하 수준 | 예상 최대 부하를 초과하는 수준 |
| 시스템 반응 | 정상 운영 확인 | 실패와 회복 과정 관찰 |
결론
- 대규모 부하 테스트와 스트레스 테스트는 서로 보완적인 성격을 지니며, 모두 중요한 성능 평가 방법이다. 대규모 부하 테스트는 시스템이 일상적인 최대 부하에서도 안정적으로 동작하는지를 확인하는 반면, 스트레스 테스트는 시스템의 한계를 넘어서는 부하에서 시스템이 어떻게 반응하고 회복하는지를 평가한다. 이 두 가지 테스트를 모두 수행함으로써 시스템의 전반적인 성능과 안정성을 더욱 철저히 평가할 수 있다.
왜 아틀러리인가?
아틀러리(Artillery)
- 간단한 설정: YAML 또는 JSON 파일을 통해 쉽게 설정할 수 있으며, 사용자 친화적인 설정 방식이다.
- Node.js 기반: 비동기 특성을 활용하여 고성능 테스트를 지원한다.
- 실시간 분석: 테스트 도중 실시간으로 결과를 모니터링하고 분석할 수 있다.
- 분산 테스트: 여러 노드에서 동시에 테스트를 수행할 수 있어 대규모 부하를 시뮬레이션하기 용이하다.
적합한 테스트 유형:
- 스트레스 테스트: 아틀러리는 설정이 간단하고, 고성능 분산 테스트를 지원하므로 시스템의 한계를 초과하는 극한 상황을 시뮬레이션하는 데 적합하다.
- 부하 테스트: 물론 아틀러리도 부하 테스트를 잘 수행할 수 있으며, 특히 간단하고 빠르게 설정이 가능하다는 장점이 있다.
JMeter
- 다양한 프로토콜 지원: HTTP, FTP, JDBC, LDAP 등 매우 다양한 프로토콜을 지원하여 다양한 유형의 애플리케이션에 대해 테스트를 수행할 수 있다.
- 풍부한 기능: 다양한 플러그인과 스크립트 언어(Groovy, Beanshell)를 사용하여 확장 가능하다.
- 분산 테스트: 초기부터 분산 테스트 기능을 지원하며, 마스터-슬레이브 아키텍처를 통해 대규모 부하를 시뮬레이션할 수 있다.
- GUI 지원: 직관적인 GUI를 통해 테스트 계획을 쉽게 작성하고 실행할 수 있다.
적합한 테스트 유형:
- 부하 테스트: JMeter는 다양한 프로토콜과 복잡한 시나리오를 지원하므로, 실제 운영 환경을 정밀하게 시뮬레이션하여 시스템의 성능을 평가하는 데 매우 적합하다.
- 스트레스 테스트: JMeter도 스트레스 테스트를 수행할 수 있지만, 설정과 관리가 다소 복잡할 수 있다. 그러나 복잡한 시나리오를 지원하는 데 강점이 있다.
결론
아틀러리는 간단한 설정과 고성능 분산 테스트를 통해 빠르고 효율적으로 스트레스 테스트를 수행하는 데 적합하다. 사용이 간편하고, 실시간 분석 기능이 있어 시스템의 한계를 쉽게 파악할 수 있다.
JMeter는 다양한 프로토콜과 복잡한 시나리오를 지원하여 부하 테스트에 매우 적합하다. GUI 지원과 풍부한 기능 덕분에 실제 운영 환경을 정밀하게 시뮬레이션하고, 시스템의 성능을 전반적으로 평가하는 데 강력한 도구이다.
설치
npm install -g artillery@latest
npm install -g artillery@canary
npx artillery dino
artillery version
실행 방법
{
"config": {
"target": "원하는 주소",
"phases": [
{
"duration": 60,
"arrivalRate": 30
}
],
"defaults": {
"headers": {
"authorization": "access token"
}
}
},
"scenarios": [
{
"name" : "test",
"flow": [
{
"get": {
"url": "url"
}
}
]
}
]
}
테스트 결과
Nginx를 통한 서버 다운 개선
최적화를 위한 첫 번째 방법으로 niginx 요청 속도 제한 구역을 설정해 최대 요청 수를 제한했다.
최적화 이전에는 앞서 말씀드린 것과 같이 35만 건 이상의 요청이 들어오면 서버가 감당하지 못하고 다운되어 버린다.
user nginx;
worker_processes auto; # 서버의 CPU 코어 수에 맞게 자동 설정
error_log /var/log/nginx/error.log warn;
pid /var/run/nginx.pid;
events {
worker_connections 1024; # 동시 연결 수 증가
multi_accept on; # 모든 새 연결을 동시에 수락
}
http {
# 요청 속도 제한을 위한 zone 설정
limit_req_zone $binary_remote_addr zone=one:10m rate=1000r/s;
include /etc/nginx/mime.types;
default_type application/octet-stream;
log_format main '$remote_addr - $remote_user [$time_local] "$request" '
'$status $body_bytes_sent "$http_referer" '
'"$http_user_agent" "$http_x_forwarded_for"';
access_log /var/log/nginx/access.log main;
sendfile on;
keepalive_timeout 65;
include /etc/nginx/conf.d/*.conf;
}
그러나 최적화 이후에는 60만 건의 요청까지 수용할 수 있으며 서버가 다운되지 않고 유지된다는 결과를 얻을 수 있었다.
이를 통해 대규모 트래픽이 발생해도 서비스를 지속할 수 있다는 것을 보장할 수 있다.
인덱스를 적용한 성능 개선
다음은 사용자에게 빠른 데이터를 제공하기 위해 복합 Indexing을 적용했다.
Indexing 적용 전의 경우 요청에 대한 응답을 생성하는 데 평균적으로 3.2초가 걸렸고 응답 성공률은 37%에 그침
적용 후에는 평균 0.36초가 걸리며 응답 성공률 또한 93%로 현저하게 향상된 것을 보실 수 있습니다.
이를 통해 저희의 최적화 방법으로 데이터에 빠르게 접근하여 사용자에게 신속한 응답을 할 수 있다는 것을 확인할 수 있었습니다.
이유는 이전에는 요청 처리 과정이 길어서 스레드풀에서 할당한 자원을 모두 다 쓰면 다음 요청은 기다리다가 timeout이 발생해서 실패하는데 지금은 빠른 처리로 인해 timeout이 발생하지 않음.
Nginx Dynamic Caching을 통한 최적화
기존에 9%만 성공하는 것을 볼 수 있음
# /api/location 경로는 캐싱 처리
location /api/locations/ {
proxy_pass http://hotsos-be:8082/locations/;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
proxy_set_header X-Forwarded-Prefix /api;
# 캐싱 설정
proxy_cache my_cache;
proxy_cache_valid 200 1h; # 200 OK 응답을 1시간 동안 캐시
# 타임아웃 설정
proxy_connect_timeout 300;
proxy_send_timeout 300;
proxy_read_timeout 300;
# 특정 조건에서 캐시를 무효화
set $bypass_cache 0;
# 캐시 무효화 조건
if ($http_cache_control = "no-cache") {
set $bypass_cache 1;
}
# CORS 설정
# add_header 'Access-Control-Allow-Origin' '*';
# add_header 'Access-Control-Allow-Methods' 'GET, POST, OPTIONS, DELETE, PUT';
# add_header 'Access-Control-Allow-Headers' 'Origin, Authorization, Accept, Content-Type, X-Requested-With';
# add_header 'Access-Control-Allow-Credentials' 'true';
# wss(web-socket) 설정
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
}
http
// CSRF 보호 기능 비활성화, 세션을 사용하지 않기때문에
.csrf((csrfConfig) ->
csrfConfig.disable()
)
// Clickjacking 공격을 방지하기 위한 X-Frame-Options 헤더 비활성화
// 캐시 제어 비활성화
.headers((headerConfig) ->
headerConfig.frameOptions(frameOptionsConfig ->
frameOptionsConfig.disable()
)
.cacheControl(cacheControl -> cacheControl.disable())
)
90% 까지 성공하는 것을 볼 수 있음
아키텍처
서비스 화면
- 홈 화면에서는 현재 위치 기반 날씨 정보 및 친구들의 안전 상태를 확인할 수 있음
- 안전상태의 경우 친구들이 각자 설정할 수 있음(하루단위로 레디스를 사용)
- 여러 친구들의 재난 문자를 볼 수 있음(각자 실시간 위치 기반 GPS)
- 각 재난시 행동 강령을 볼 수 있음
- AED와 대피소를 현재 위치 기반으로 찾을 수 있음
- 원하는 지역이나 건물 등 검색 가능
- 여러 게시글을 조회할 수 있음
- 이때 일정 수치의 사실 버튼을 누르면 해당 지역의 사람들에게 알림이 전송됨
- 알람을 보낼 때 gpt를 활용하여 재난의 위험성을 판단함
시연 영상
홈 화면
게시물 등록
욕설 필터링 기능 적용
재난문자 알림
재난 문자 상세
재난 문자 필터
핫 게시물 등록
지도
마무리
이번 프로젝트를 하면서 많은 것을 배웠고 재미있었다.
팀원들이 다들 열심히 해서 좋은 결과물을 얻었고 뿌듯한 것 같다.
2주 넘게 야근을 한 것 같다..
프로젝트 동안 새로운 기술을 적용해보기도 하고 새로운 지식도 얻어서 더 의미가 있었다.
현재도 다른 프로젝트를 진행 중인데 꾸준히 열심히 하자.