
최소 신장 트리
-> 최소 신장 트리를 대표하는 알고리즘으로는 프림 알고리즘과 크루스칼 알고리즘이 존재한다.
프림 알고리즘(Prim’s Algorithm)
프림 알고리즘은 로버트 프림(Robert C. Prim)이 만든 최소 신장 트리 알고리즘이다. 프림 알고리즘은 최소 신장 트리에 연결된 정점 주변에 있는 간선의 가중치 중 가장 작은 것을 골라 최소 신장 트리를 만드는 방법이다. 프림 알고리즘으로 최소 신장 트리를 만드는 방법은 다음과 같은 방식으로 동작한다.
- 그래프와 비어 있는 최소 신장 트리를 만듦
- 임의의 정점을 시작 정점으로 선택하고 최소 신장 트리의 루트 노드로 삽입
- 최소 신장 트리에 삽입된 정점과 이 정점과 인접한 정점의 가중치를 확인해서 가장 작은 가중치를 최소 신장 트리에 삽입. (최소 신장 트리에 삽입 시 사이클이 형성되지 않게 삽입)
- 3번 과정을 반복한 후 모든 정점이 최소 신장 트리에 연결되면 종료
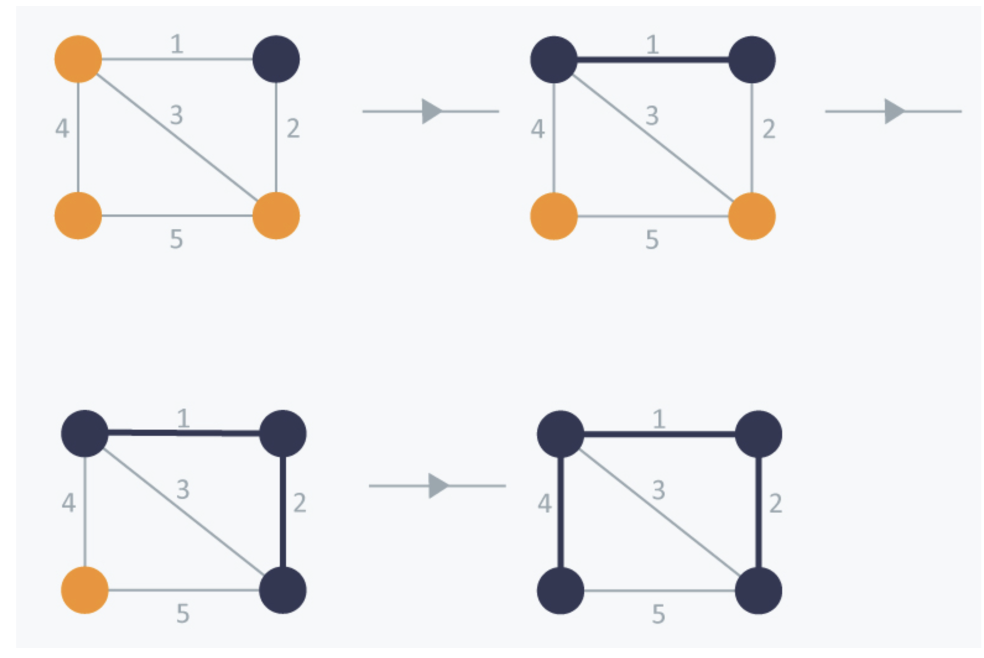
임의의 점을 시작점으로 잡는다. 위의 경우에는 오른쪽 위 점을 시작점으로 잡았다.
이후 간선의 가중치중 작은 간선을 선택한다. 즉 왼쪽 위 점을 연결한다.
이후 연결되어 있는 정점에서 가장 작은 간선을 연결한다. 이때는 4, 3 ,2 중에 가장 작은 2를 고를 수 있다.
2를 연결한 후 다시 연결되어 있는 정점에서 가장 작은 간선을 선택한다. 이때는 4, 3 ,5 가 남아있다.
가장 작은 간선이 3이지만, 3을 연결하면 사이클이 생기기 때문에 제외한다. 그러므로 4를 연결하여 MST를 만들 수 있다.
다른 예시로는 아래 그림을 들 수 있다.

프림 알고리즘 구현하기
초기 상태로 정점(=노드)은 서로 연결되어 있지 않다. 정점과 연결된 간선을 하나씩 추가하면서 MST를 만든다.
프림 알고리즘은 시작 정점을 정해 우선순위 큐에 넣는다. 우선순위 큐에는 (정점, 가중치) 형식으로 저장되며, 첫 시작은 (시작 정점, 0)으로 넣는다.
우선순위 큐가 빌 때까지 아래를 반복한다.
1. 우선순위 큐에서 하나를 꺼낸다. 꺼낸 정점을 v라고 한다.
2. v가 이미 MST에 포함되어 있다면 1로 돌아간다. 아니면 3으로 넘어간다.
3. v와 연결된 간선을 모두 살핀다. 간선 (w, cost)는 v와 정점 w 사이 연결된 간선이며 cost 가중치를 가진다. 만약 w를 방문하지 않았다면 우선순위 큐에 추가한다.
import java.util.ArrayList;
import java.util.List;
import java.util.PriorityQueue;
import java.util.Scanner;
public class Main {
static List<Node>[] graph;
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
graph = new ArrayList[n + 1];
for (int i = 0; i < graph.length; i++) {
graph[i] = new ArrayList<>();
}
for (int i = 0; i < m; i++) {
int from = sc.nextInt();
int to = sc.nextInt();
int cost = sc.nextInt();
graph[from].add(new Node(to, cost));
graph[to].add(new Node(from, cost));
}
System.out.println(prim(1, n));
}
private static int prim(int start, int n) {
boolean[] visited = new boolean[n + 1];
PriorityQueue<Node> pq = new PriorityQueue<>();
pq.offer(new Node(start, 0));
int sum = 0;
while (!pq.isEmpty()) {
Node node = pq.poll();
int v = node.w;
int cost = node.cost;
if (visited[v]) {
continue;
}
visited[v] = true;
sum += cost;
for (Node link : graph[v]) {
if (!visited[link.w]) {
pq.offer(link);
}
}
}
return sum;
}
}
class Node implements Comparable<Node> {
int w;
int cost;
public Node(int w, int cost) {
this.w = w;
this.cost = cost;
}
@Override
public int compareTo(Node o) {
return this.cost - o.cost;
}
}
크루스칼 알고리즘(Kruskal’s Algorithm)
크루스칼 알고리즘은 그래프 내의 모든 간선의 가중치를 확인하고 가장 작은 가중치부터 확인해서 최소 신장 트리를 만드는 방법이다. 크루스칼 알고리즘은 그리디를 사용한다.
크루스칼 알고리즘으로 최소 신장 트리를 만드는 방법은 다음과 같이 동작한다.
- 그래프 내의 모든 간선의 가중치를 오름차순으로 정렬
- 오름차순으로 정렬된 가중치를 순회하면서 최소 신장 트리에 삽입 (최소 신장 트리에 삽입 시 사이클이 형성되지 않게 삽입)
크루스칼 알고리즘에서 사이클을 확인하기 위해 분리집합을 사용합니다. 분리 집합은 다음과 같이 서로 공통된 원소를 갖지 않는 집합을 의미한다.

최소 신장 트리에서 다음과 같은 집합이 있고 1-2를 간선으로 연결할 경우, 왼쪽은 서로 다른 집합이기 때문에 1-2를 연결해도 사이클이 형성되지 않지만, 오른쪽은 이미 같은 집합에 속해 있기 때문에 1-2를 연결할 경우 사이클을 형성하게 된다. 이렇게 하면 쉽게 사이클을 확인할 수 있다.

예시를 통해 동작과정을 살펴보자.

간선을 작은 순으로 선택한다. 처음에는 가장 작은 1이 선택되었다.
이후에는 2, 3 이 선택되었다. 이후 4를 선택하려 하였지만, 4를 선택할 경우 사이클이 발생하기 때문에 5를 연결한 모습이다.

가중치를 정렬시킨 모습이다.

작은 순으로 선택하며, 만약 사이클이 형성될 경우 선택하지 않는다.
크루스칼 알고리즘 구현하기
초기 상태로 정점(=노드)은 서로 연결되어 있지 않다. 간선을 하나씩 추가하면서 MST를 만든다. 크루스칼 알고리즘을 수행하고 완성된 그래프는 최소 신장 트리이다. 간선을 추가하는 방식은 다음과 같다.
1. 크기 가장 작은 간선부터 모든 간선을 살핀다. 이때 간선은 가중치에 대해 오르차순으로 정렬되어 있다.
2. 간선을 그래프에 포함했을 때, MST에 사이클이 생기지 않으면 추가한다. 이 과정은 유니온 파인드 알고리즘을 이용한다.
정점 v와 정점 w를 잇는 간선 e가 있을 때, 정점 v와 정점 w가 같은 부모 노드를 가진다면 간선 e는 MST에 추가하지 않는다.
import java.util.Arrays;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int n = sc.nextInt();
int m = sc.nextInt();
int[][] graph = new int[m][3];
for (int i = 0; i < m; i++) {
graph[i][0] = sc.nextInt(); //간선 나가는 정점
graph[i][1] = sc.nextInt(); //간선 들어오는 정점
graph[i][2] = sc.nextInt(); //가중치
}
Arrays.sort(graph, (s1, s2) -> s1[2] - s2[2]);
int[] parent = new int[n + 1];
for (int i = 0 ; i < parent.length; i++) {
parent[i] = i;
}
System.out.println(kruskal(graph, parent));
}
private static int kruskal(int[][] graph, int[] parent){
int cost = 0;
for (int i = 0; i < graph.length; i++) {
if (find(parent, graph[i][0]) != find(parent,graph[i][1])){
cost += graph[i][2];
union(parent,graph[i][0],graph[i][1]);
}
}
return cost;
}
private static int find(int[] parent, int n) {
if (parent[n] == n) {
return n;
}
return find(parent, parent[n]);
}
private static void union(int[] parent, int x, int y) {
x = find(parent,x);
y = find(parent,y);
if (x < y) {
parent[y] = x;
return;
}
parent[x] = y;
}
}
최소 신장 트리 구현 문제 풀러 가기
https://www.acmicpc.net/problem/1197
1197번: 최소 스패닝 트리
첫째 줄에 정점의 개수 V(1 ≤ V ≤ 10,000)와 간선의 개수 E(1 ≤ E ≤ 100,000)가 주어진다. 다음 E개의 줄에는 각 간선에 대한 정보를 나타내는 세 정수 A, B, C가 주어진다. 이는 A번 정점과 B번 정점이
www.acmicpc.net

아래는 프림 알고리즘을 사용하여 푼 결과이고, 위는 크루스칼 알고리즘을 사용하여 푼 결과이다.
저 문제에서는 성능 차이가 크게 나지는 않는 것으로 보인다.
하지만 두 알고리즘의 성능이 그래프의 특성과 구현 방식에 따라 달라질 수 있기 때문에 어느 상황에 어떤 알고리즘을 사용하는 것이 좋은가?
일반적으로, 그래프의 정점의 개수를 V, 간선의 개수를 E라고 할 때, 프림 알고리즘은 밀집 그래프에 적합하고, 크루스칼 알고리즘은 회소 그래프에 적합하다. 따라서 간선의 개수가 적은 희소 그래프의 경우에는 크루스칼 알고리즘이 프림 알고리즘보다 성능이 좋을 수 있다.
그러나 간선의 개수가 많은 밀집 그래프의 경우에는 프림 알고리즘이 효율적일 수 있다.
'PS > 알고리즘' 카테고리의 다른 글
| 비트마스크(BitMask) (2) | 2023.01.20 |
|---|---|
| 동적계획법(DP) (2) | 2022.12.20 |
| 다익스트라 (0) | 2022.12.18 |
| 너비 우선 탐색(BFS) (1) | 2022.11.14 |
| 깊이 우선 탐색(DFS) (2) | 2022.11.06 |